🧠 Introduction (try Free) In immersive VR environments, maintaining scene consistency during interactive exploration is crucial but challenging. Many systems rely on either inpainting with explicit geometry—leading to drift—or limited-window video models that lose long-term coherence. To tackle this, VMem introduces Surfel‑Indexed View Memory, an innovative memory module that anchors past views to 3D surface
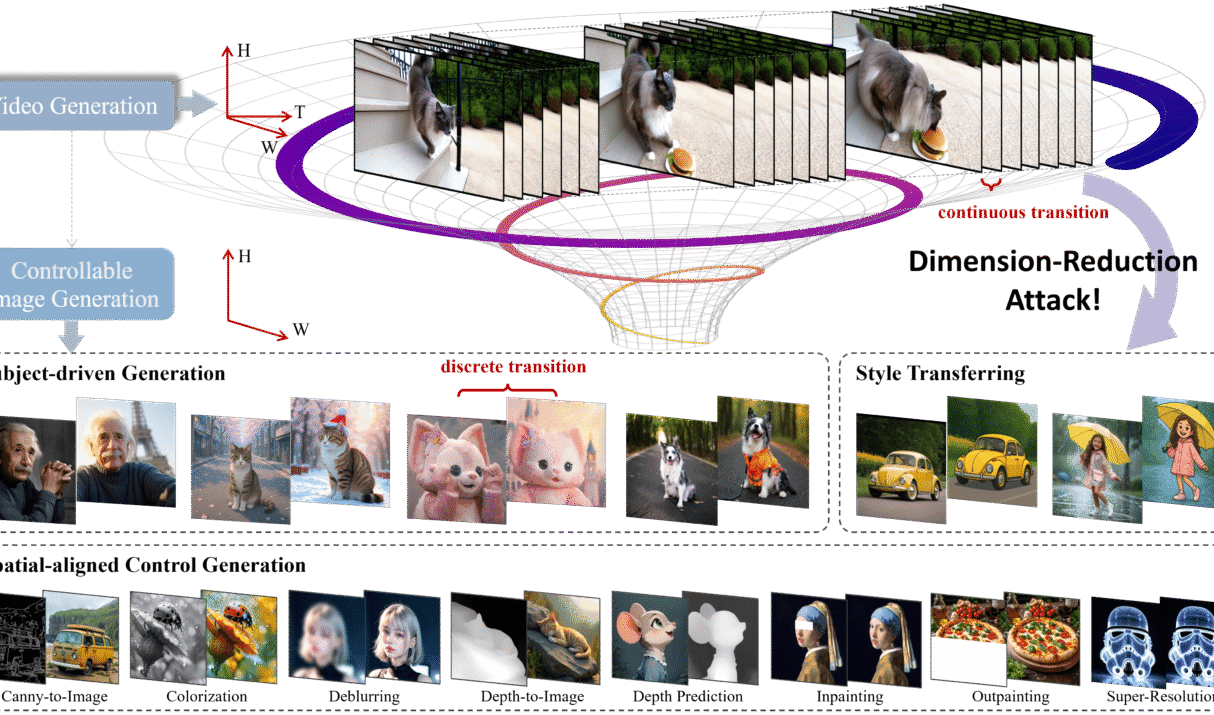
🚀 Introduction (try Online Free) Video generative models have long been prized for their ability to simulate dynamic, continuous interactions—essentially functioning as “world simulators” that weave together visual, temporal, spatial, and causal information. This richness prompts an exciting question: Can knowledge from these high-dimensional video models be repurposed for precise image generation? Enter Dimension-Reduction Attack

🚀 Introduction Generative modeling has witnessed significant advancements with the emergence of diffusion and flow-based models, which have set new benchmarks in generating high-quality images. However, these models often require numerous sampling steps to produce satisfactory results, leading to increased computational costs and slower inference times. On the other hand, consistency models aim to distill

🌌 Introduction: Polaris — A New Dawn in Reinforcement Learning for Advanced Reasoning Models In the ever-evolving landscape of artificial intelligence, the pursuit of models that can reason with human-like precision has been both a challenge and a triumph. Enter Polaris — an innovative, open-source post-training framework that harnesses the power of reinforcement learning (RL)
🧠 Introduction Overview:Introduce InterActHuman as a novel diffusion transformer (DiT)-based framework that enables multi-concept, audio-driven human video generation. Highlight its ability to overcome traditional single-entity limitations by localizing and aligning multi-modal inputs for each distinct subject. Emphasize the use of an iterative, in-network mask predictor to infer fine-grained, spatio-temporal layouts for each identity, allowing precise
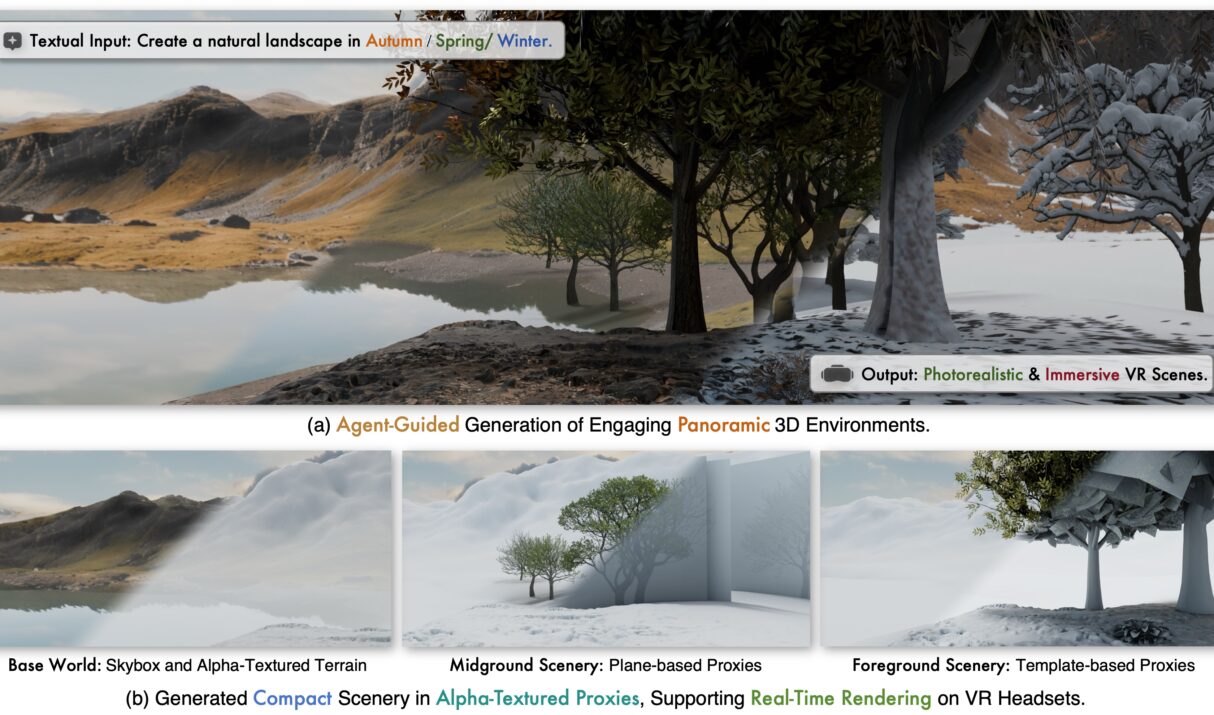
📝 Introduction ImmerseGen is an AI-driven framework developed by PICO (ByteDance) in collaboration with Zhejiang University for immersive virtual reality world generation. It harnesses agent-guided workflows to synthesize complete panoramic VR environments from simple text prompts—like “a serene lakeside”, “autumn forest with chirping birds”, or “futuristic cityscape.”Unlike conventional high-poly modeling or volumetric approaches, ImmerseGen uses