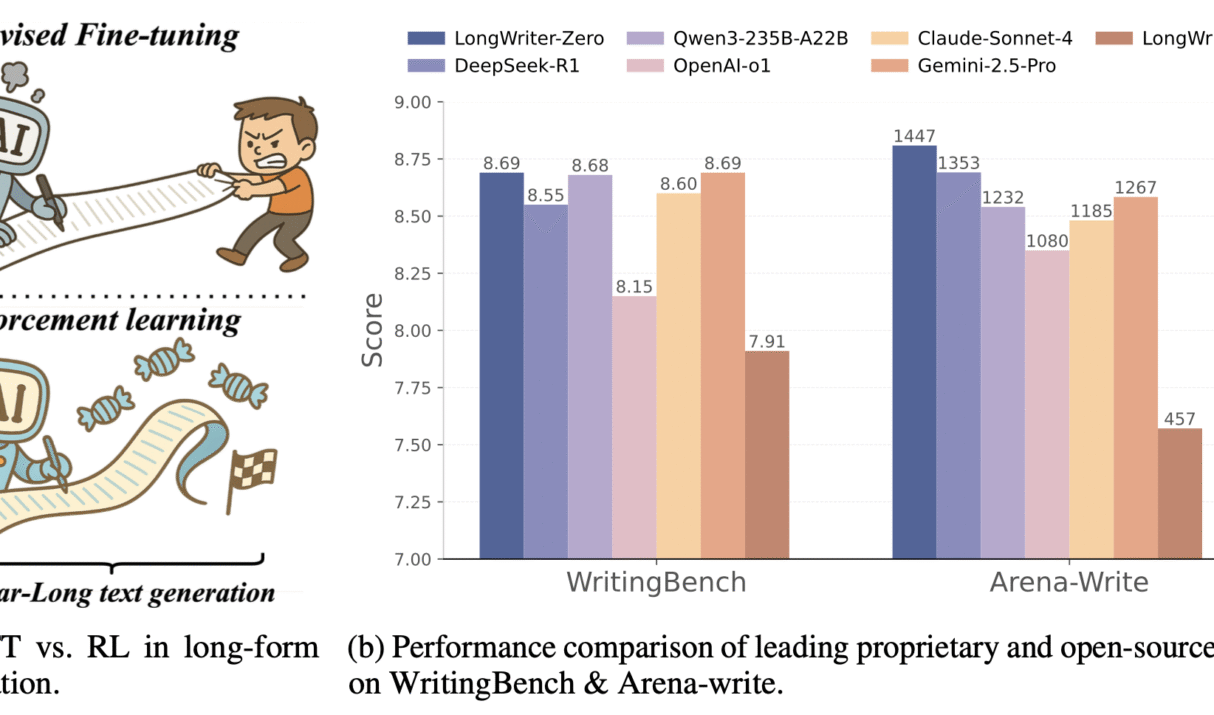
Introduction: In the realm of natural language processing, generating coherent and contextually rich content over extended passages has long been a formidable challenge. Traditional language models often falter when tasked with producing ultra-long texts, typically due to limitations in training data and inherent architectural constraints. Enter LongWriter-Zero, a groundbreaking model developed by researchers at Tsinghua

🧠 Introduction DreamCube is an innovative framework designed to generate high-quality 3D panoramic scenes from single-view RGB-D inputs and multi-view text prompts. This approach addresses the challenges of limited 3D panoramic data by leveraging pre-trained 2D foundation models. By applying Multi-plane Synchronization, DreamCube adapts these 2D models for omnidirectional content generation, ensuring diverse appearances and
🧠 Introduction AnimateAnyMesh is a pioneering framework that enables the generation of high-quality, temporally consistent 4D animations from arbitrary 3D meshes using natural language prompts. This innovation addresses the challenges of spatio-temporal modeling complexity and the scarcity of 4D training data, which have traditionally hindered the creation of dynamic 3D content. 🔧 Core Components 🧩
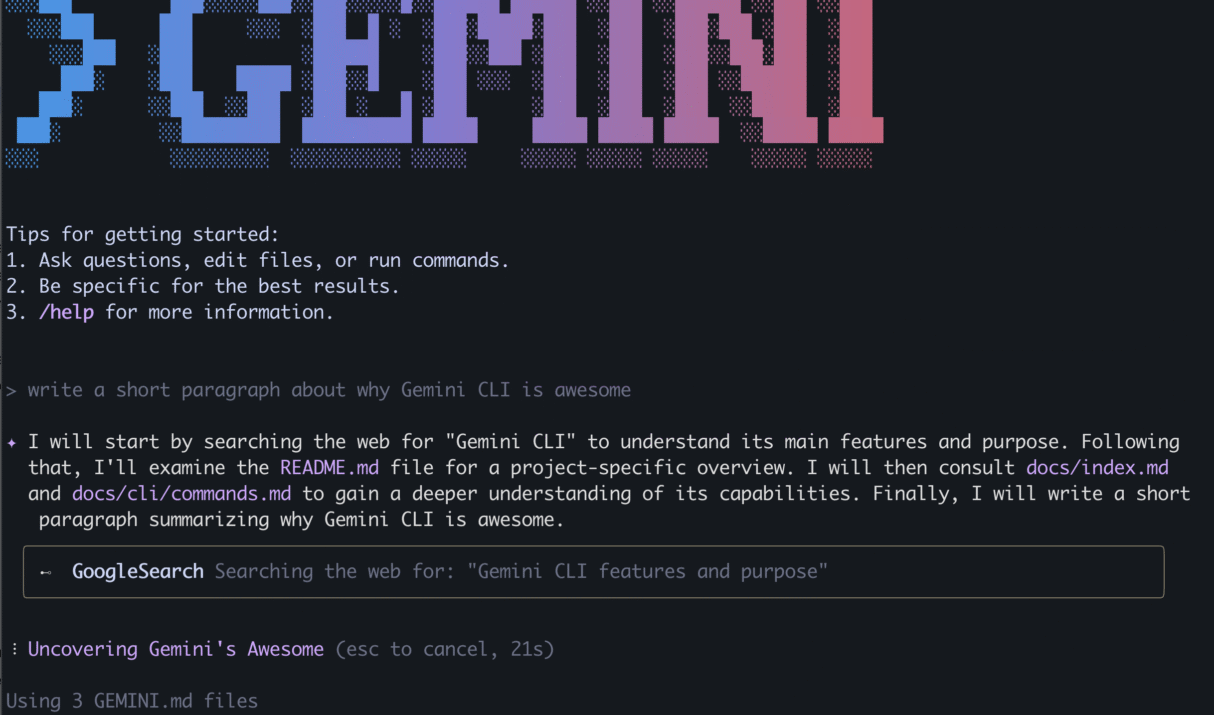
🧠 Introduction Say goodbye to copy-pasting into AI chat windows—Gemini CLI brings Google’s latest Gemini 2.5 Pro model right into your terminal. This open-source, cross-platform (Windows, macOS, Linux) tool empowers developers to: Best of all? It’s free—each Google account gets a generous 60 queries per minute and 1,000 daily requests under the Gemini Code Assist
🧠 Introduction Animating 3D models—especially those with complex skeletal structures—has traditionally been a laborious process, requiring either rigid rigs or expensive optimizations in deformation spaces. AnimaX revolutionizes this by leveraging the rich motion knowledge embedded in video diffusion models and translating it into controllable 3D animations. At its core, AnimaX interprets motion as a sequence
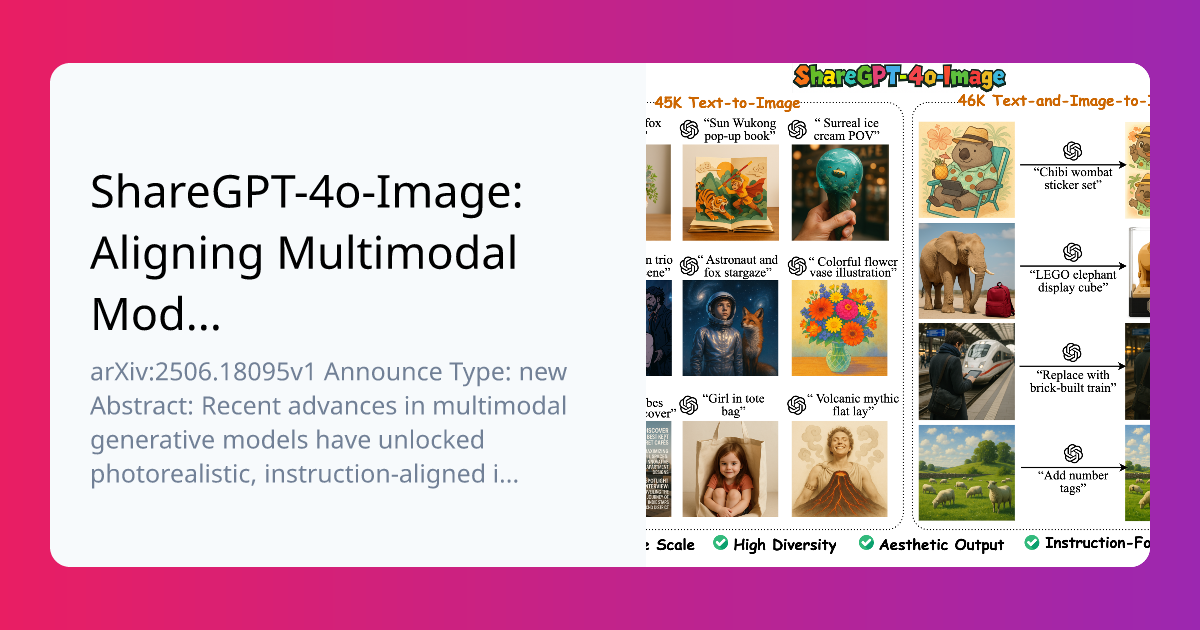
🧠 Introduction to ShareGPT-4o-Image ShareGPT-4o-Image is a groundbreaking large-scale multimodal dataset comprising 92,256 high-quality image generation samples. These samples were meticulously crafted using GPT-4o, OpenAI’s advanced multimodal model, which integrates vision, language, and reasoning capabilities. The dataset is designed to facilitate the development of open-source multimodal models that align with GPT-4o’s image generation prowess. 🔍