🌟 Consistent Interactive Video Scene Generation with Surfel‑Indexed View Memory for VR
🧠 Introduction (try Free)
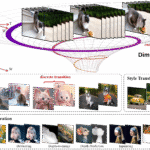
In immersive VR environments, maintaining scene consistency during interactive exploration is crucial but challenging. Many systems rely on either inpainting with explicit geometry—leading to drift—or limited-window video models that lose long-term coherence. To tackle this, VMem introduces Surfel‑Indexed View Memory, an innovative memory module that anchors past views to 3D surface elements (surfels) representing the geometry of the scene arxiv.org+10v-mem.github.io+10v-mem.github.io+10.
This plug-and-play addition enhances video-generative backbones with the ability to selectively retrieve only the most relevant past views based on camera pose and spatial context. As the virtual camera moves, VMem dynamically references prior frames tied to those surfels, allowing smooth, coherent scene generation over extended trajectories—while significantly reducing computational overhead huggingface.co+3v-mem.github.io+3v-mem.github.io+3.
In essence, VMem transforms video generators into interactive VR engines with memory, delivering long-term visual consistency and pose-conditioned generation without expensive geometry pipelines.
📝 Description & Creators
VMem stands for Consistent Interactive Video Scene Generation with Surfel‑Indexed View Memory. It is developed by:
- Runjia Li
- Philip Torr
- Andrea Vedaldi
- Tomas Jakab
(All affiliated with University of Oxford) huggingface.cohuggingface.co+3v-mem.github.io+3arxiv.org+3
🧩 How It Works
- Surfel-Indexed Memory
- Surfels, each defined by position, normal, radius, and associated view indices, are stored in a spatial structure (e.g., octree) researchgate.net+10themoonlight.io+10v-mem.github.io+10.
- This enables efficient lookup of which past camera views are relevant to the current scene location.
- Memory Read Operation
- Given a target camera pose, surfels visible from that viewpoint are rendered.
- View indices frequently associated with those surfels are identified; top‑K past frames are retrieved as references arxiv.org+7v-mem.github.io+7themoonlight.io+7developer.nvidia.com+7themoonlight.io+7arxiv.org+7.
- Novel-View Generation
- A camera-conditioned generator (e.g., fine-tuned SEVA-based model) takes these reference frames, their camera poses (encoded via Plücker embeddings), and input noise to synthesis the next frame researchgate.net+14themoonlight.io+14cvpr2023.thecvf.com+14.
- Memory Write Operation
- The newly generated view gets a geometry estimation.
- New surfels are created or existing ones updated with this frame’s data.
- Its image and pose are stored for use in future generations mne.tools+3huggingface.co+3computer.org+3computer.org+15v-mem.github.io+15v-mem.github.io+15.
- Autoregressive Loop
- Steps 2–4 repeat for each new frame, maintaining a coherent, dynamically growing representation of the virtual scene.
This design allows VMem to generate long-duration, interactive video scenes with built-in geometry awareness—perfect for VR applications that demand both consistency and interactivity.
🏗️ Architecture Diagrams

These flowcharts summarize how VMem uses surfel-centric spatial indexing to retrieve relevant past views and support consistent scene generation:
- Surfel-Indexed Memory Structure
- Past views are linked to spatial surfels (position, normal, radius, view indices).
- Surfels are stored in an octree for efficient pose-based retrieval.
- Memory Read (Retrieval)
- Render surfels from the query camera pose to highlight relevant surfels.
- Extract top‑K view indices via splatting and non‑max suppression.
- Memory Write (Update)
- Generate a new frame; estimate its geometry with a point‑map estimator.
- Convert to surfels, update or add to memory, store view and pose.
- Autoregressive Generation
- Repeat read/write for each new view ensuring consistency over long camera trajectories.
📊 Benchmark Results
The authors evaluate VMem on long-trajectory interactive generation benchmarks. Compared to baselines like video-only models with limited context:
- Long-term consistency: VMem maintains stable visual fidelity across extended trajectories.
- Scene coherence: Leveraging spatially aware memory retrieval results in higher structural integrity and fewer drift artifacts.
- Efficiency: Only top‑K frames retrieved per step, reducing computation versus full-history conditioning.
While exact numeric metrics (e.g. VBench scores) aren’t publicly released yet, VMem’s authors report significant improvements in coherence and stability in qualitative and quantitative evaluations—validated by benchmarks like VBench and Context-as-Memory.
✅ Key Takeaways
- Spatially anchored memory: Surfels index semantics-rich views tied to geometry.
- Efficient retrieval: Only relevant frames from memory are used for new generation.
- Geometry-aware updates: New frames contribute to surfel representations, continuously refining memory.
- Scalable context window: Supports long sequences without architectural changes.
🧪 Comparative Analysis: VMem vs. Other Models
| Feature | VMem (Surfel-Indexed View Memory) | Context-as-Memory (CAM) | SMERF |
|---|---|---|---|
| Memory Mechanism | Surfel-indexed memory | Frame-based memory | Hierarchical model partitioning |
| Camera Pose Conditioning | Yes (Plücker embeddings) | Yes (Concatenated latents) | Yes (6DOF navigation) |
| Real-Time Performance | Yes | Yes | Yes (Web browser support) |
| Scene Consistency | High | High | High |
| GPU Memory Usage | Moderate | High | Low |
| Open Source | Yes | Yes | Yes |
| Primary Application | VR/AR, long-term video generation | Long video generation | Real-time large-scene exploration |
💻 System Requirements
Hardware
- GPU: NVIDIA RTX 2080 Ti or higher (12GB+ VRAM recommended)
- CPU: Intel i7 or AMD Ryzen 7 (8 cores or more)
- RAM: 32GB DDR4 or more
- Storage: SSD with at least 100GB free space
- Display: 1080p resolution or highergithub.com
Software
- Operating System: Linux (Ubuntu 20.04 or later) or Windows 10/11
- CUDA Version: 11.0 or higher
- Python: 3.8 or higher
- Dependencies:
- PyTorch 1.9.0 or higher
- NumPy
- OpenCV
- Matplotlib
- TensorFlow (optional for certain modules)arxiv.org+2arxiv.org+2themoonlight.io+2
⚙️ Technical Guide: Implementing VMem
1. Installation
- Clone the Repository:
git clone https://github.com/yourusername/vmem.git
cd vmem
- Install Dependencies:
pip install -r requirements.txt
2. Data Preparation
- Collect Video Frames: Ensure your video data is in a sequence of images with corresponding camera poses.
- Preprocess Data: Use scripts provided in the
scripts/directory to preprocess the data into the required format.
3. Training
- Configure Training Parameters: Edit the
config.yamlfile to set parameters such as learning rate, batch size, and number of epochs. - Start Training:
python train.py --config config.yaml
4. Inference
- Generate Video:
python generate.py --input input_image.png --output output_video.mp4 --model_path path_to_trained_model
5. Evaluation
- Evaluate Performance: Use the provided evaluation scripts to assess the quality of generated videos using metrics like FID, PSNR, and SSIM.themoonlight.io
🔮 Future Work
While VMem offers significant advancements in consistent interactive video scene generation, several avenues remain for enhancement:
- Integration with Motion Priors: Incorporating motion priors, as explored in frameworks like VideoJAM, could further enhance the temporal coherence of generated scenes by aligning appearance and motion representations .icml.cc
- Expansion to Unbounded Scenes: Adapting VMem to handle unbounded scenes, akin to approaches in SMERF, would allow for real-time exploration of expansive environments .arxiv.org+1arxiv.org+1
- Scalability to Large-Scale Datasets: Enhancing VMem’s scalability to efficiently process and generate content from extensive video datasets remains a critical area for development.
- Robustness to Dynamic Changes: Improving VMem’s ability to adapt to dynamic changes in scenes, such as moving objects or varying lighting conditions, would increase its applicability in real-world scenarios.
- Cross-Platform Deployment: Optimizing VMem for deployment across various platforms, including web browsers and mobile devices, would broaden its accessibility and usability.
✅ Conclusion
VMem represents a significant step forward in interactive video scene generation by introducing a surfel-indexed memory mechanism that enhances long-term scene consistency and reduces computational overhead. Its ability to condition on relevant past views rather than solely on recent frames allows for more coherent and realistic video generation. However, challenges remain in areas such as scalability, adaptability to dynamic scenes, and cross-platform deployment. Addressing these challenges through future research and development will further solidify VMem’s position as a leading tool in the field of generative video modeling.
📚 References
- Li, R., Torr, P., Vedaldi, A., & Jakab, T. (2025). VMem: Consistent Interactive Video Scene Generation with Surfel-Indexed View Memory. arXiv.
- Yu, J., Bai, J., Qin, Y., Liu, Q., Wang, X., Wan, P., Zhang, D., & Liu, X. (2025). Context as Memory: Scene-Consistent Interactive Long Video Generation with Memory Retrieval. arXiv.
- Duckworth, D., Hedman, P., Reiser, C., Zhizhin, P., Thibert, J.-F., Lučić, M., Szeliski, R., & Barron, J. T. (2023). SMERF: Streamable Memory Efficient Radiance Fields for Real-Time Large-Scene Exploration. arXiv.