
🧠 TAIR Explained: Fixing Text‑Image Blurs with Diffusion Restore

Introduction
In everyday visual data—think storefronts, street signs, documents—textual regions often carry critical meaning. While diffusion models have excelled at general image restoration, they typically struggle when it comes to restoring text accurately. Instead, they tend to hallucinate text-like shapes that look plausible but are incorrect—imagine a blurry shop sign that becomes gibberish after restoration.
The recent ArXiv (June 11, 2025) paper titled “Text‑Aware Image Restoration with Diffusion Models” (TAIR), authored by a team led by Jaewon Min, Jin Hyeon Kim, Paul Hyunbin Cho, and others from KAIST, Korea University, Yonsei, and Samsung, addresses this exact challenge
What is TAIR?
TAIR defines a new restoration task that demands both visual fidelity and textual accuracy—not just recovering image quality but ensuring embedded text remains readable and correct
Who is behind it?
The work is a collaborative effort among prominent institutions:
- KAIST AI (Min, Cho, Kim, Kim),
- Korea University (Kim),
- Yonsei University (Lee),
- Samsung Electronics (Park, Park, Park)
Why is this important?
Conventional diffusion restoration networks achieve high perceptual quality, but in text regions, they often produce plausible yet fabricated characters, a risk known as text-image hallucination. This type of error isn’t just aesthetic—it can render text unintelligible, undermining practical applications such as OCR, document digitization, and AR navigation.
To address this, the authors:
- Introduce TAIR, emphasizing the joint optimization of image and text restoration.
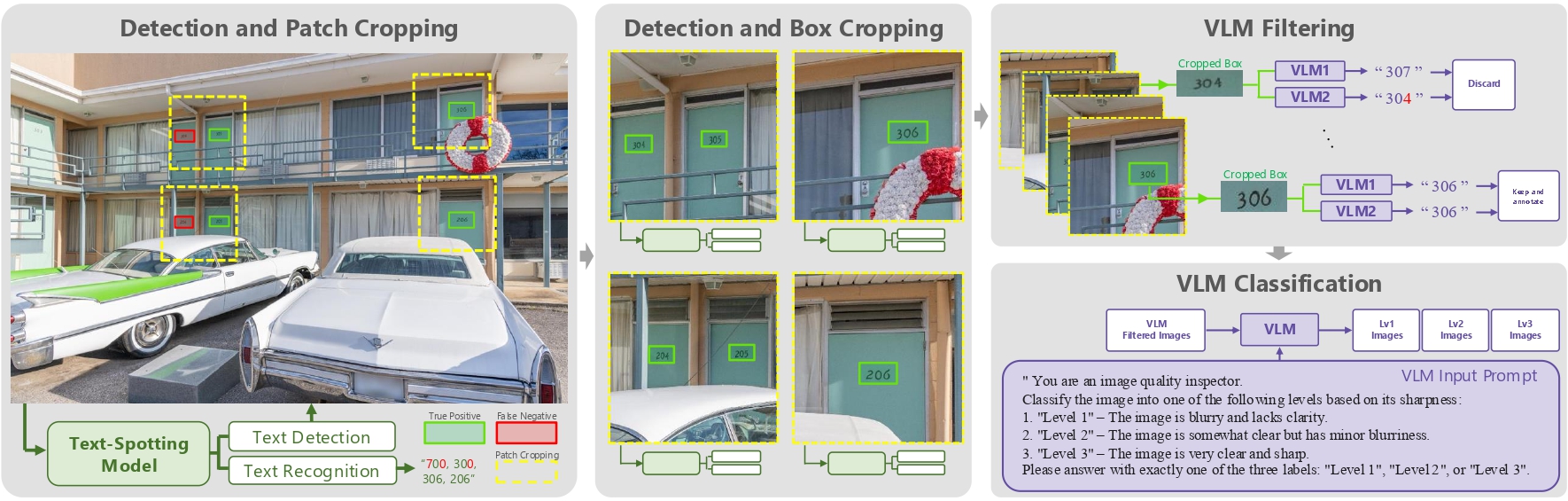
- Create SA-Text, a new benchmark dataset of 100,000 real-world scene images, densely annotated with complex and diverse text instances
- Propose TeReDiff, a multi-task diffusion model that integrates a text-spotting module into the diffusion backbone and uses recognized text as denoising prompts—effectively guiding restoration to preserve textual integrity
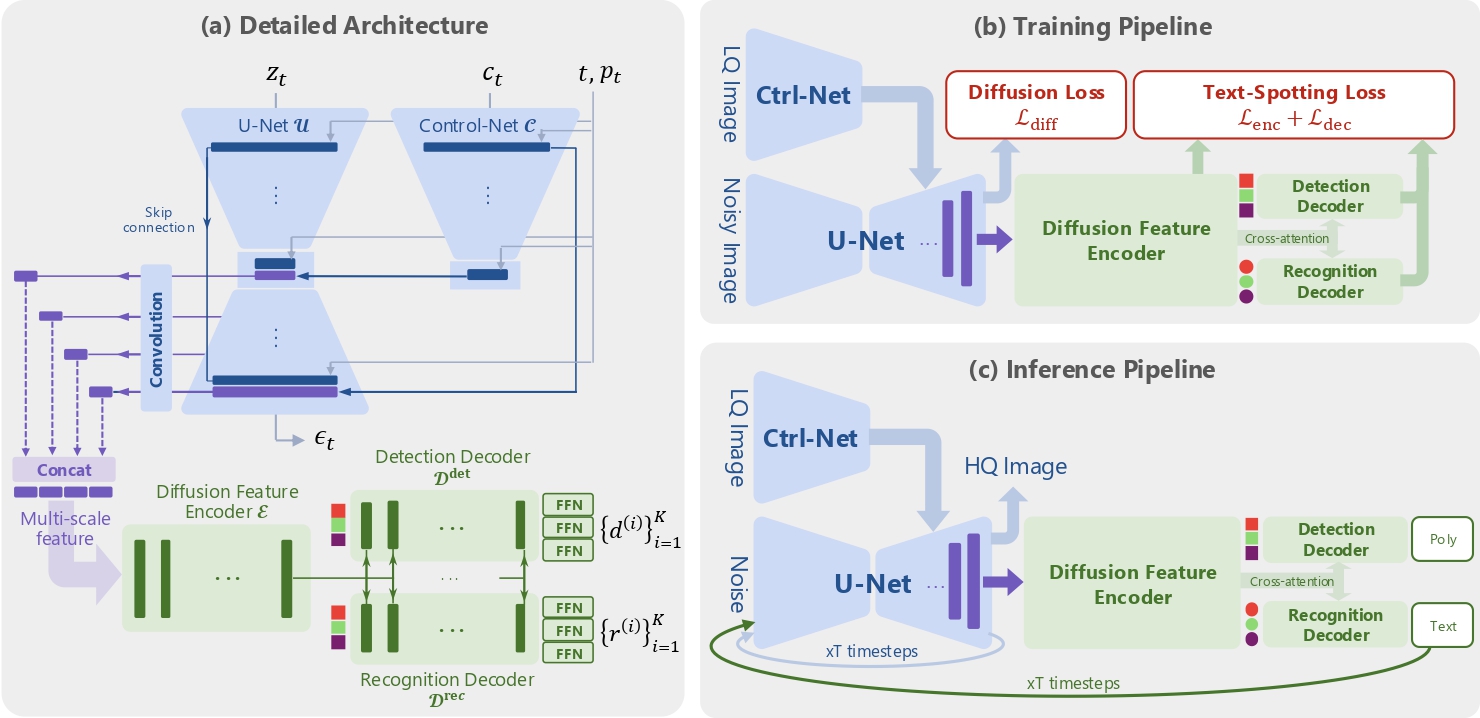
TeReDiff Architecture: A Deep Dive 🔍
TeReDiff (Text Restoration Diffusion) is the core innovation of TAIR, built as a multi-task diffusion framework that marries image restoration with text-spotting through a unified architecture. Here’s how it all fits together:
1. Restoration Backbone
- U‑Net style diffusion model (e.g., Stable Diffusion or SD2.1), optionally enhanced with ControlNet modules like DiffBIR, performs the progressive denoising of degraded inputs.
- The low-quality (LQ) image is encoded via a VAE encoder into a conditioning latent, ccc, and added to the noisy latent ztz_tzt at each timestep.
2. Integrated Text‑Spotting Module
- A transformer-based encoder-decoder (similar to DETR/TESTR style) is plugged directly into the diffusion U-Net. It receives intermediate multi-scale features from decoder blocks via light conv layers.
- This module predicts both bounding polygons and character-level transcriptions for all visible text instances—a coordinated text detection and recognition head within the diffusion pipeline.
3. Text-Prompted Diffusion Loop
- At each diffusion timestep ttt, the text‑spotter outputs recognized strings {r(i)}\{r^{(i)}\}{r(i)}, which are formatted into a prompt ptp_tpt using a predefined template.
- The denoising network is then conditioned on this prompt—tightly coupling image restoration with explicit text guidance, helping avoid text hallucinations.
4. Multi-Stage Training & Losses

5. Training & Inference Pipeline Summary
| Step | Process |
|---|---|
| Input | Degraded image (512×512 crop) |
| Encoding | VAE encodes to latent ccc; U-Net adds noise ztz_tzt |
| Feature Extraction | U-Net decoder features → text-spotter encoder |
| Text Prediction | Detector finds polygons; recognizer obtains text for prompt |
| Prompt Creation | Recognized strings → formatted prompt ptp_tpt |
| Denoising | Denoiser conditioned on zt,c,ptz_t, c, p_tzt,c,pt → zt−1z_{t-1}zt−1 |
Why TeReDiff Excels
- Semantic guidance: Text prompts ensure plausibility and textual accuracy, directly reducing hallucinations.
- Rich representations: Leveraging internal diffusion features improves text detection and recognition over conventional backbones.
- Joint optimization: Multi-stage training aligns both image fidelity and text comprehension, yielding state-of-the-art performance in both domains
🧠 Text-Aware Restoration: TAIR vs. TADiSR & DiffTSR
| Model | Approach | Key Metric (OCR‑based) | Performance Highlights |
|---|---|---|---|
| TeReDiff (TAIR) | Joint diffusion + text-spotting + text-prompting | +10.1 F1 over previous SOTA | Achieves E2E F1 = 24.4 on SA‑Text Level‑2, vs DiffBIR’s 19.6 |
| TADiSR | Joint decoders with segmentation-guided losses | OCR accuracy ≈ 0.882 on Real‑CE | Strong text fidelity in lab settings |
| DiffTSR | Diffusion + text super-resolution | Strong Chinese text accuracy | Effective for single-language SR |
✅ TeReDiff stands out with its integrated design: a diffusion backbone + transformer-based text-spotting + prompt conditioning loop, enabling it to significantly outperform TADiSR and DiffTSR by over 10% F1 in key benchmarks
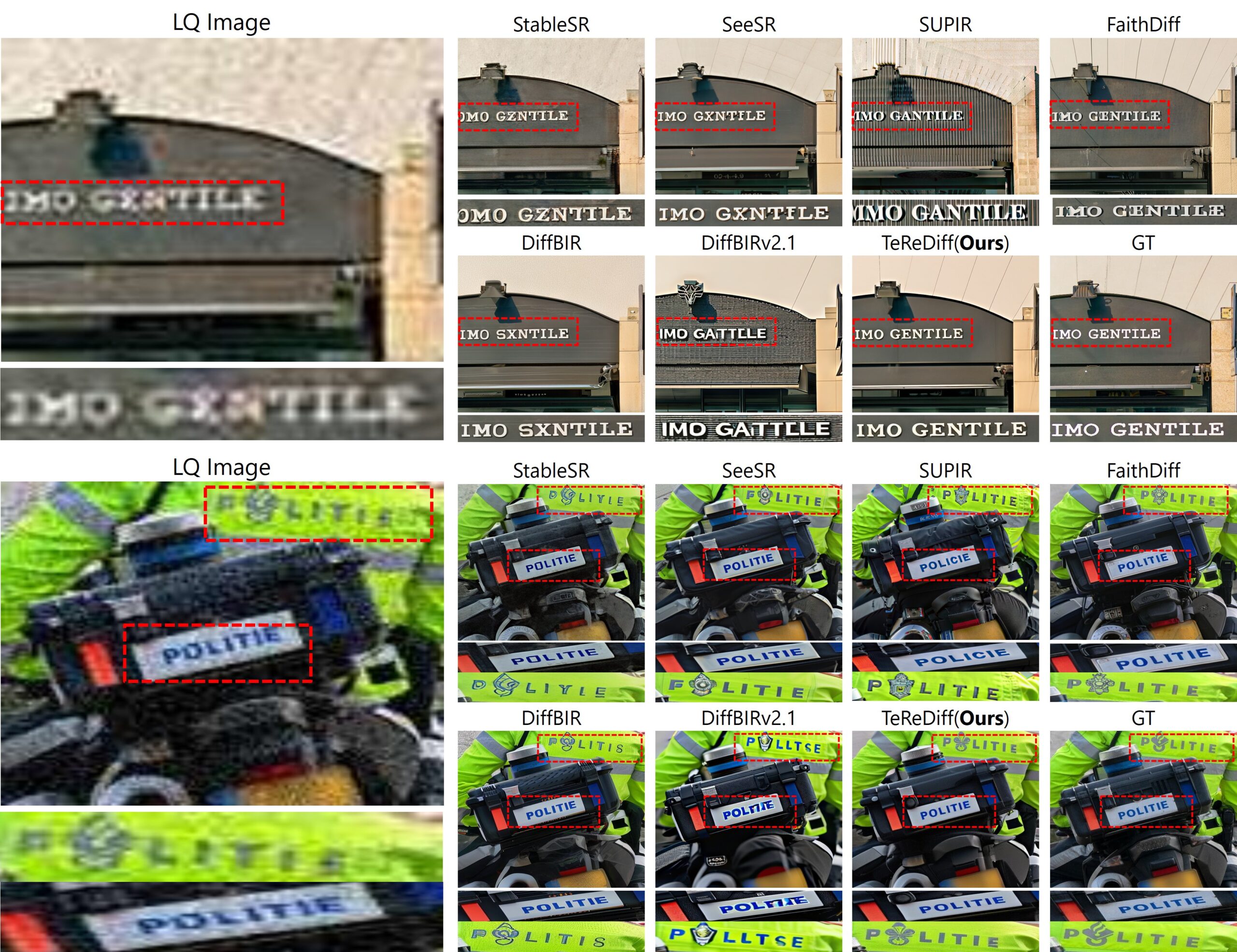
🎨 General Image Restoration: TeReDiff vs. DiffBIR, FaithDiff, Real‑ESRGAN, SeeSR
- General denoising/SR models like DiffBIR, FaithDiff, SeeSR, and Real‑ESRGAN excel in perceptual enhancements (PSNR/SSIM, LPIPS, FID).
- However, under text-heavy degradation, they produce plausible-looking but incorrect text (“hallucinations”), as evidenced by lower OCR accuracy.
- TeReDiff, in contrast, trades minimal perceptual performance loss to ensure textual accuracy, achieving SOTA in both detection and recognition on SA‑Text and Real‑Text datasets.
📄 Document & Scene Text Restoration: PreP‑OCR vs. TAIR
- PreP‑OCR (heritage/document pipelines combining restoration + linguistic post-processing) achieves 63–70% character error rate reduction.
- But TAIR’s TeReDiff surpasses this in scene text contexts by leveraging 100K real-world images (SA‑Text) and the prompted diffusion loop, excelling in multilingual and unconstrained environments.
🛠️ Why TeReDiff Leads the Pack
- Holistic multi-task training: integrates image restoration and text spotting in one pipeline.
- Prompt-conditioned reversal: Text predictions guide denoising at each iteration—reducing hallucination.
- Rich feature-sharing: Text-spotting leverages diffusion’s internal features, outperforming ResNet-style backbones.
- Extensive benchmarking: outperforming prior SOTA on both image fidelity and text-based metrics
🧰 Open‑Source Details
- The official TAIR GitHub repository is hosted under the KAIST CVLab and provides the TeReDiff model code, training scripts, and usage instructions: GitHub:
cvlab‑kaist/TAIR - The SA‑Text dataset is also open-source, hosted via Hugging Face, including 100K scene images with polygon-level text and transcription annotations: Dataset: Hugging Face
Min‑Jaewon/SA‑Text(training split ≈ 119K examples)
These resources allow you to fully reproduce training, fine-tuning, or inference with TeReDiff for text-aware image restoration.
⚙️ Hardware & Software Requirements
The repository includes instructions, but based on typical diffusion model setups and similar projects (like Real-ESRGAN, SUPIR), here are the expected minimum requirements:
Software:
- OS: Linux (Ubuntu 20.04 recommended) or macOS
- Frameworks:
- Python 3.8+
- PyTorch 1.12+
- NVIDIA CUDA Toolkit 11.x for GPU acceleration
- Other dependencies:
transformers,timm,diffusers,datasets, etc. (installable viarequirements.txtin the repo)
Hardware:
- GPU: NVIDIA GPU with ≥ 16 GB VRAM (e.g., RTX 3090, A40) — needed for high-res diffusion and text-spotting features
- RAM: At least 32 GB system memory, ideally 64 GB, to accommodate dataset loading and training pipelines
- Disk space:
- Dataset: SA‑Text raw images + annotations ≈ 12.6 GB compressed
- Model checkpoints: VAE + U-Net + text-spotter ≈ 10–20 GB depending on model size
🧭 Quick Setup Checklist
- Clone the repo:
git clone https://github.com/cvlab‑kaist/TAIR.git - Install Python dependencies:
cd TAIR pip install -r requirements.txt - Download SA‑Text dataset via Hugging Face:
from datasets import load_dataset ds = load_dataset('Min-Jaewon/SA-Text') - Prepare GPU environment (CUDA drivers,
torch.cuda.is_available()should returnTrue). - Run example inference script on a sample degraded image:
python inference.py --input low_quality.jpg --output restored.jpg --ckpt te_re_diff.pth
💡 Notes & Tips
- Using multiple GPUs (e.g., 2× A40/3090) can improve training speed and enable larger batch sizes.
- If you lack a high-memory GPU, try gradient checkpointing or mixed-precision (AMP) training to reduce resource load.
- Smaller-scale experiments (e.g., only inference or fine-tuning on limited datasets) may run on GPUs as small as 12 GB VRAM (e.g. RTX 3060 Ti), with reduced batch sizes.
🔮 Future Directions
Based on the TAIR paper and its evaluation across benchmarks, the authors and broader community highlight several promising research avenues:
- Robustness to Small or Highly Degraded Text
Current performance dips when text is tiny, blurred, or heavily degraded. Future work may involve targeted data augmentation, attention refinements, or sub-pixel prompt strategies to better handle such cases arxiv.org+15emergentmind.com+15thismoment.ai+15. - Out-of-Distribution & Complex Scenes
Models like TeReDiff struggle with OOD input (e.g., rare fonts, extreme noise, motion blur). Expanding SA-Text or incorporating more diverse training sets—plus domain adaptation techniques—could improve generalization arxiv.org+9emergentmind.com+9thismoment.ai+9. - Advanced Prompting Architectures
The current design uses simple string prompts from recognized text. Future research might explore structured prompts (e.g., bounding-box metadata, style descriptors) or multimodal guidance to enhance feedback loops emergentmind.com. - Low-Cost & Efficient Deployment
Diffusion models are computationally intensive. Optimizing for efficient inference, model pruning, and mobile or embedded GPU deployment could broaden real-world applicability . - Real-World Application Integration
Scaling TAIR to modules that feed into OCR, AR, accessibility tools, or video frameworks—along with latency constraints—poses both engineering and research challenges arxiv.orgarxiv.org+6emergentmind.com+6thismoment.ai+6.
✅ Conclusion
TAIR (Text‑Aware Image Restoration) introduces a novel paradigm shift in the image restoration landscape: from purely perceptual quality to preserving semantic readability. By releasing the SA‑Text dataset and proposing TeReDiff—a joint diffusion-spotting architecture using text prompts—the authors demonstrate:
- State-of-the-art results in both text detection and end-to-end recognition on scene text benchmarks ar5iv.labs.arxiv.org+6emergentmind.com+6arxiv.org+6.
- Strong resilience against common text hallucination errors, a major weakness in generic restoration models reddit.com+15emergentmind.com+15arxiv.org+15.
- A clear direction for further innovation in efficient prompting, low-resource deployment, and robust adaptation to realistic conditions.
TAIR stands as a key milestone for information-preserving restoration, and its open-source artifacts pave the way for future breakthroughs.
📚 References
- Min et al., “Text‑Aware Image Restoration with Diffusion Models,” ArXiv, June 11, 2025 emergentmind.comemergentmind.com+7arxiv.org+7cvlab-kaist.github.io+7.
- SA‑Text dataset, large-scale benchmark of 100K annotated images emergentmind.com+5arxiv.org+5cvlab-kaist.github.io+5.
- EmergentMind, Overview of TAIR, results, and future directions ar5iv.labs.arxiv.org+5emergentmind.com+5emergentmind.com+5.
- ThisMoment.ai, Highlights including human study, performance, and AR/OCR applications thismoment.ai+1emergentmind.com+1.
- Prior surveys on diffusion-based IR, pointing out OOD and efficiency challenges emergentmind.com+2arxiv.org+2ar5iv.labs.arxiv.org+2.

