🧠🔄🧱 ShapeLLM-Omni: Bridging 3D Understanding with Multimodal Intelligence (Generate 3D icons from prompts and Sample Image )
✨ Introduction
The world of artificial intelligence is evolving rapidly. With the recent release of GPT-4o, we’ve seen just how powerful multimodal models can be—especially when it comes to combining text and image understanding. But there’s a major piece missing: 3D content.
3D is everywhere—games, design, virtual reality, robotics—and yet, until now, language models couldn’t natively understand or generate it. That’s why we’re excited to introduce ShapeLLM-Omni, a groundbreaking multimodal LLM that brings true 3D-native understanding and generation into the fold.
Created by Junliang Ye, Zhengyi Wang, Ruowen Zhao, Shenghao Xie, and Jun Zhu, this model is a major step toward making language-based 3D interaction as easy as talking to ChatGPT.
📌 What is ShapeLLM-Omni?
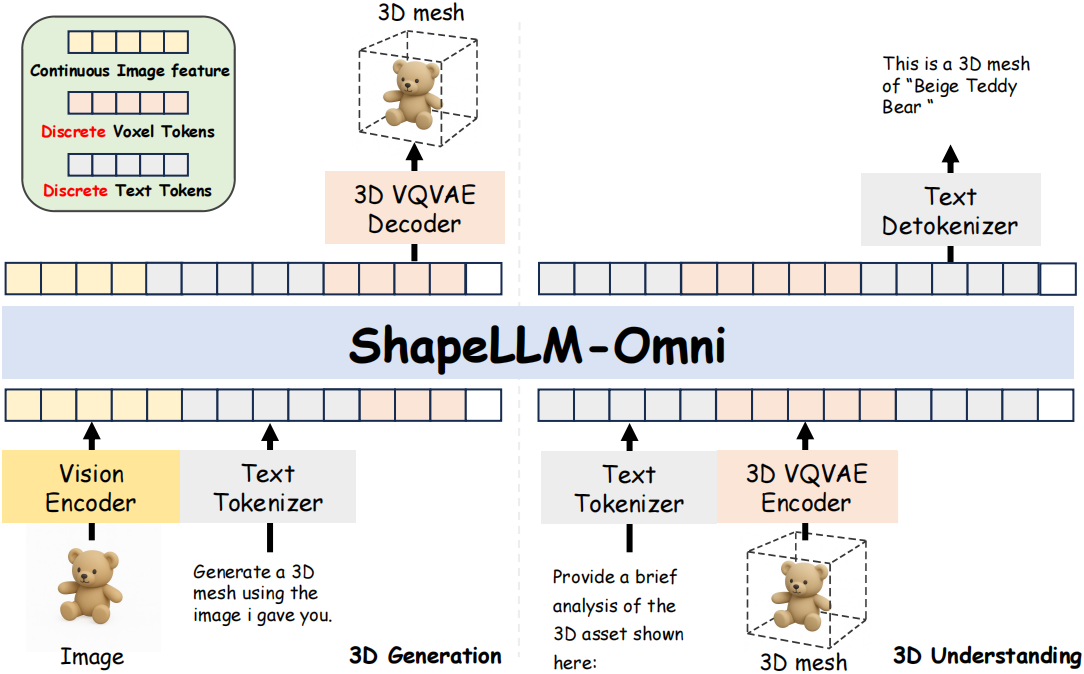
ShapeLLM-Omni is a native multimodal large language model built specifically to work with 3D assets. Unlike models limited to text and 2D images, ShapeLLM-Omni can:
- Understand 3D shapes
- Generate 3D models from text
- Edit 3D scenes with language instructions
- Provide natural language descriptions of 3D assets
This is made possible by combining deep learning innovations with a specially designed 3D dataset and encoder system.
🧠 How It Works
At its core, ShapeLLM-Omni uses:
🧱 A 3D Vector-Quantized VAE (VQ-VAE)
- Encodes 3D shapes into discrete tokens.
- Enables accurate and compact shape representation.
📚 The 3D-Alpaca Dataset
- A large-scale multimodal dataset for training.
- Covers tasks like 3D generation, comprehension, and editing.
🤖 Qwen-2.5-vl-7B-Instruct
- A vision-language LLM fine-tuned with 3D-Alpaca.
- Enables instruction-following and generation capabilities in 3D environments.
🧩 What ShapeLLM-Omni Can Do
Here are just a few of the model’s impressive multimodal abilities:
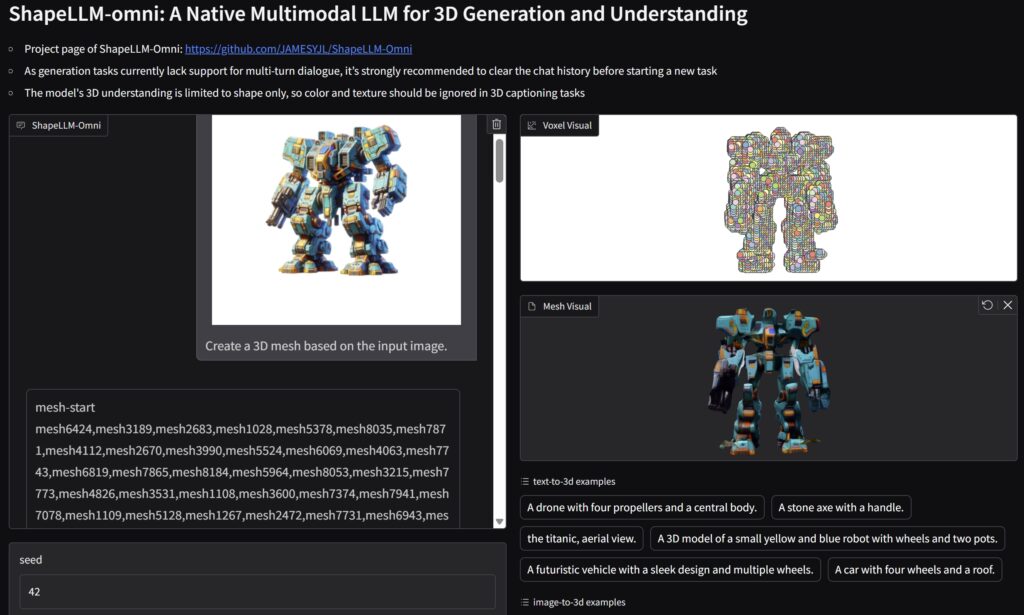
- Text → 3D Model
“Generate a cube with rounded corners and a hollow center.” - Image → 3D Conversion
Upload a 2D sketch, get a 3D model in return. - 3D Editing with Natural Language
“Move the chair closer to the table and change its color to red.” - 3D → Text Description
“A low-poly tree with five branches and round leaves.”
These capabilities open doors for intuitive 3D design, simulation, and more.
🌍 Why This Matters
ShapeLLM-Omni is more than a tech demo—it’s a glimpse into the future of spatial computing. By enabling LLMs to interact with 3D data, we can:
- Simplify 3D content creation in gaming, design, and animation.
- Improve accessibility for creators with limited technical skills.
- Create better simulations in fields like medicine, education, and robotics.
- Enable richer human-AI interactions in XR/AR environments.
📊 Performance Highlights
While technical benchmarks are still evolving, ShapeLLM-Omni has demonstrated:
- High-quality shape reconstruction from discrete tokens.
- Instruction-following performance on par with top multimodal models.
- Fast generation and comprehension across multiple 3D tasks.
(A full paper is available on arXiv)
📁 Inside the 3D-Alpaca Dataset
One of the key enablers of this model is the 3D-Alpaca dataset, which includes:
- 3D-text paired data
- Instructional editing examples
- Semantic tasks like captioning
- Diverse object categories and scenes
This dataset is available for open research and provides a solid foundation for future 3D AI models.
🧰 Open Source and How to Use It (TRY ONLINE LINK)
You can access ShapeLLM-Omni on GitHub, including:
- Pretrained model checkpoints
- Sample input-output demos
- Instructions for fine-tuning or inference
- 3D-Alpaca dataset download
It supports standard formats like .obj, .glb, and .ply for seamless integration.
Certainly! Here’s a comprehensive guide to the installation requirements for ShapeLLM-Omni, including both hardware specifications and software dependencies.
🖥️ Hardware Requirements
To run ShapeLLM-Omni efficiently, consider the following hardware specifications:
Minimum Specifications
- CPU: Multi-core processor (e.g., Intel i7 or AMD Ryzen 7)
- GPU: NVIDIA RTX 3060 or equivalent with at least 12GB VRAM
- RAM: 16GB
- Storage: SSD with at least 100GB of free space
Recommended Specifications
- CPU: High-performance multi-core processor (e.g., Intel i9 or AMD Ryzen 9)
- GPU: NVIDIA RTX 3090 or A100 with 24GB or more VRAM
- RAM: 32GB or more
- Storage: 1TB NVMe SSD for optimal performance
Note: While ShapeLLM-Omni can function without a GPU, utilizing one significantly enhances performance, especially for large models.
💻 Software Requirements
Ensure your system meets the following software prerequisites:
- Operating System: Linux (Ubuntu 20.04 or newer)
- Python: 3.10 or higher
- CUDA: 11.2 or newer (for GPU acceleration)
- PyTorch: 2.2.0 or newer
- Additional Libraries:
- torchvision==0.17.0
- torchaudio==2.2.0
- litgpt==0.4.3
- snac==1.2.0
- soundfile==0.12.1
- openai-whisper
- tokenizers==0.19.1
- streamlit==1.37.1
- pydub==0.25.1
- onnxruntime==1.19.0
- numpy==1.26.3
- gradio==4.42.0
- librosa==0.10.2.post1
- flask==3.0.3
- fire
Note: These dependencies are specified in the requirements.txt file of the ShapeLLM-Omni repository.
🛠️ Installation Steps
Follow these steps to set up ShapeLLM-Omni:
- Clone the Repository:
git clone https://github.com/JAMESYJL/ShapeLLM-Omni.git cd ShapeLLM-Omni
- Set Up a Python Virtual Environment:
python3 -m venv shapellm-env source shapellm-env/bin/activate
- Install Dependencies:
pip install -r requirements.txt
- Download Pre-trained Models:
Follow the instructions in the repository’s README to download the necessary model weights. - Run the Application:
python app.py
⚠️ Additional Notes
- GPU Usage: For optimal performance, especially during inference, a CUDA-compatible GPU is recommended. Ensure that your system has the appropriate NVIDIA drivers and CUDA toolkit installed.
- Storage Space: Ensure you have sufficient storage space, as model weights and datasets can occupy several gigabytes.
- Dependencies: Some dependencies may require additional system libraries. Refer to the official documentation of each library for installation instructions.
⚠️ Limitations & Future Directions
Like all research, this is just the beginning. Current limitations include:
- Relatively low resolution in generated shapes
- High GPU requirements for inference
- Limited support for complex animations or rigging
The team aims to improve scalability, integrate animation, and explore 3D + image + text trinity fusion.
🔮 Future Work
While ShapeLLM-Omni marks a significant milestone in integrating 3D understanding into large language models, it also opens up exciting possibilities for further research and development. Some key future directions include:
1. Higher-Resolution 3D Generation
- Current outputs are limited in fidelity due to tokenization and computational constraints.
- Future work can focus on:
- Multi-scale VQ-VAE architectures.
- Mesh-level and voxel-super-resolution techniques.
- Texture and material synthesis for photorealism.
2. Temporal & Animated 3D Assets
- ShapeLLM-Omni currently handles static 3D objects.
- Enabling 4D reasoning (3D + time) would allow:
- Generation of animated scenes.
- Simulation of motion, deformation, and physical interactions.
- Integration into game engines and AR/VR pipelines.
3. Multimodal Fusion: Image + Text + 3D
- While ShapeLLM-Omni supports 3D and text, deeper integration with image inputs (e.g., sketches, photographs) could enhance:
- Multi-source guided generation.
- Sketch-to-3D workflows.
- Enhanced visual grounding in 3D captioning.
4. Interactive & Real-Time Editing
- The ability to modify 3D content with natural language in real-time could revolutionize tools for:
- Designers and 3D artists.
- Architects and engineers.
- Educators and students in virtual labs.
5. Cross-Modal Reasoning and Commonsense in 3D
- Future versions could focus on:
- Spatial reasoning (e.g., “Can the cup fit inside the box?”).
- Physical intuition (e.g., balance, gravity, collisions).
- Object affordances (e.g., “Can you sit on it?”).
6. Scaling Up the 3D-Alpaca Dataset
- Expanding the dataset to include:
- More diverse object categories.
- Outdoor and architectural scenes.
- Real-world CAD and industrial data.
7. Energy Efficiency & Edge Deployment
- 3D models are computationally intensive.
- Future work could explore:
- Lighter architectures for deployment on edge devices (e.g., AR headsets).
- Quantization and distillation methods.
- Cloud-streamed inference with 3D rendering.
8. Generalization to Unseen Modalities
- ShapeLLM-Omni’s native token structure could serve as a base for further extensions:
- 3D + Audio (e.g., simulate environmental soundscapes).
- 3D + Haptics for robotics.
- 3D + Lidar or point clouds for autonomous systems.
9. Open Benchmarking & Evaluation Metrics
- The field still lacks standardized benchmarks for:
- Instructional 3D editing.
- Multi-turn dialogue with 3D objects.
- Semantic and structural accuracy in 3D generation.
✅ Conclusion
ShapeLLM-Omni is an exciting step toward a new kind of AI—one that can not only read and see but also imagine and build in three dimensions. With models like this, the future of intuitive 3D design, spatial computing, and digital creativity looks incredibly bright.