🔗 ShareGPT-4o-Image: Which is Trained on Chat-GPT 4.0

🧠 Introduction to ShareGPT-4o-Image
ShareGPT-4o-Image is a groundbreaking large-scale multimodal dataset comprising 92,256 high-quality image generation samples. These samples were meticulously crafted using GPT-4o, OpenAI’s advanced multimodal model, which integrates vision, language, and reasoning capabilities. The dataset is designed to facilitate the development of open-source multimodal models that align with GPT-4o’s image generation prowess.
🔍 Dataset Composition
The dataset is divided into two primary categories:
- Text-to-Image Generation: 45,717 samples where detailed textual descriptions are transformed into corresponding images.
- Text-and-Image-to-Image Generation: 46,539 samples that involve modifying or enhancing existing images based on textual instructions.
Each image is generated at a resolution of 1024×1024 pixels, ensuring high fidelity and detail. The accompanying text descriptions range from simple object labels to complex scene compositions, providing a rich training ground for multimodal models.
🧪 Dataset Creation Process
The creation of ShareGPT-4o-Image involved several key steps:
- Data Collection: A diverse set of images was curated from various domains to ensure broad coverage and representation.
- Prompt Engineering: Custom prompts were crafted to guide GPT-4o in generating descriptive captions for each image.
- Image Generation: GPT-4o’s advanced image generation capabilities were leveraged to create high-quality images based on the prompts.
- Annotation: Each generated image was paired with its corresponding textual description, forming a multimodal dataset suitable for training and evaluation.
This meticulous process ensures that ShareGPT-4o-Image is a valuable resource for advancing the field of multimodal AI.
🤖 Janus-4o: A Model Trained on ShareGPT-4o-Image
Building upon the ShareGPT-4o-Image dataset, researchers developed Janus-4o, a multimodal large language model (MLLM) capable of both text-to-image and text-and-image-to-image generation. Fine-tuned from the Janus-Pro-7B model using the ShareGPT-4o-Image dataset, Janus-4o demonstrates significant improvements over its predecessor, including enhanced image quality and the ability to generate images from both text prompts and combined text and image inputs.
Janus-4o’s development underscores the importance of high-quality, large-scale datasets in training effective multimodal models. By aligning with GPT-4o’s image generation capabilities, Janus-4o sets a new standard for open multimodal models, offering researchers and developers a powerful tool for exploring and advancing multimodal AI applications.
📝 Description of ShareGPT-4o-Image
ShareGPT-4o-Image is a meticulously curated multimodal dataset comprising 92,256 high-quality image generation samples, all synthesized using GPT-4o’s advanced image generation capabilities. This dataset aims to bridge the gap between proprietary AI models and open research by providing a resource that aligns with GPT-4o’s strengths in visual content creation.
📊 Dataset Composition
The dataset is divided into two primary categories:
- Text-to-Image Generation: 45,717 samples where detailed textual descriptions are transformed into corresponding images.
- Text-and-Image-to-Image Generation: 46,539 samples that involve modifying or enhancing existing images based on textual instructions.
Each image is generated at a resolution of 1024×1024 pixels, ensuring high fidelity and detail.
🧪 Dataset Creation Process
The creation of ShareGPT-4o-Image involved several key steps:
- Data Collection: A diverse set of images was curated from various domains to ensure broad coverage and representation.
- Prompt Engineering: Custom prompts were crafted to guide GPT-4o in generating descriptive captions for each image.
- Image Generation: GPT-4o’s advanced image generation capabilities were leveraged to create high-quality images based on the prompts.
- Annotation: Each generated image was paired with its corresponding textual description, forming a multimodal dataset suitable for training and evaluation.
This meticulous process ensures that ShareGPT-4o-Image is a valuable resource for advancing the field of multimodal AI.
🤖 Janus-4o: A Model Trained on ShareGPT-4o-Image
Building upon the ShareGPT-4o-Image dataset, researchers developed Janus-4o, a multimodal large language model (MLLM) capable of both text-to-image and text-and-image-to-image generation. Fine-tuned from the Janus-Pro-7B model using the ShareGPT-4o-Image dataset, Janus-4o demonstrates significant improvements over its predecessor, including enhanced image quality and the ability to generate images from both text prompts and combined text and image inputs.
Janus-4o’s development underscores the importance of high-quality, large-scale datasets in training effective multimodal models. By aligning with GPT-4o’s image generation capabilities, Janus-4o sets a new standard for open multimodal models, offering researchers and developers a powerful tool for exploring and advancing multimodal AI applications.
🔍 Comparative Analysis: ShareGPT-4o-Image & Janus-4o-7B vs. Other Multimodal Models
| Feature | ShareGPT-4o-Image & Janus-4o-7B | GPT-4o | DALL·E 3 | Midjourney | Gemini 2.5 Pro |
|---|---|---|---|---|---|
| Model Type | Dataset & Fine-tuned Model | Multimodal LLM (Text, Image, Audio) | Text-to-Image | Text-to-Image | Multimodal LLM (Text, Image) |
| Primary Strengths | High-quality image generation with contextual understanding | Advanced multimodal capabilities with conversational refinement | Artistic and stylized image generation | Photorealistic and artistic image generation | Fast image generation with conversational editing |
| Image Generation Quality | High fidelity, photorealistic images | Superior image quality with nuanced details | High-quality images with artistic flair | Exceptional photorealism and creative control | Good image quality with rapid generation |
| Text Rendering in Images | Accurate and coherent text integration | Flawless text rendering in images | Historically weaker, improved in DALL·E 3 | Weak in complex text rendering | Good, but potentially not as strong as GPT-4o |
| Editing Capabilities | Conversational refinement within ChatGPT | Seamless conversational editing within ChatGPT | Requires separate interface or prompting for variations | Primarily focused on generating new images | Offers image editing capabilities |
| Speed | Moderate (prioritizes quality) | Slower (up to a minute) | Generally faster | Can vary depending on complexity | Fastest |
| Accessibility | Open-source dataset and model | Integrated into ChatGPT, available across tiers | Available through ChatGPT and API | Primarily through Discord | Integrated into Google products, API access available |
| Style Focus | Versatile, strong in photorealism and utility | Versatile, strong in photorealism and utility | Balanced | Strong in artistic, moody, and hyperrealistic styles | Versatile |
🧠 Key Takeaways
- ShareGPT-4o-Image provides a high-quality dataset that enables the development of models like Janus-4o-7B, which excels in generating photorealistic images with contextual understanding.
- GPT-4o offers advanced multimodal capabilities, including conversational refinement and seamless integration of text, image, and audio inputs.
- DALL·E 3 is known for its artistic and stylized image generation, with improvements in text rendering capabilities.
- Midjourney stands out for its exceptional photorealism and creative control, making it a favorite among artists and designers.
- Gemini 2.5 Pro delivers fast image generation with conversational editing features, suitable for quick iterations and creative exploration.
🧱 Architecture Overview
ShareGPT-4o-Image Dataset Creation Pipeline
The ShareGPT-4o-Image dataset was constructed using a systematic approach:
- Prompt Generation: Utilizing Gemini-Pro-2.5, a large multimodal model, to generate diverse and descriptive prompts.
- Image Generation: Feeding these prompts into GPT-4o’s image generation system to produce high-quality images.
- Data Structuring: Organizing the generated images and their corresponding prompts into a structured dataset for further training and evaluation.
This pipeline ensures a diverse and high-quality dataset, facilitating the development of advanced multimodal models.
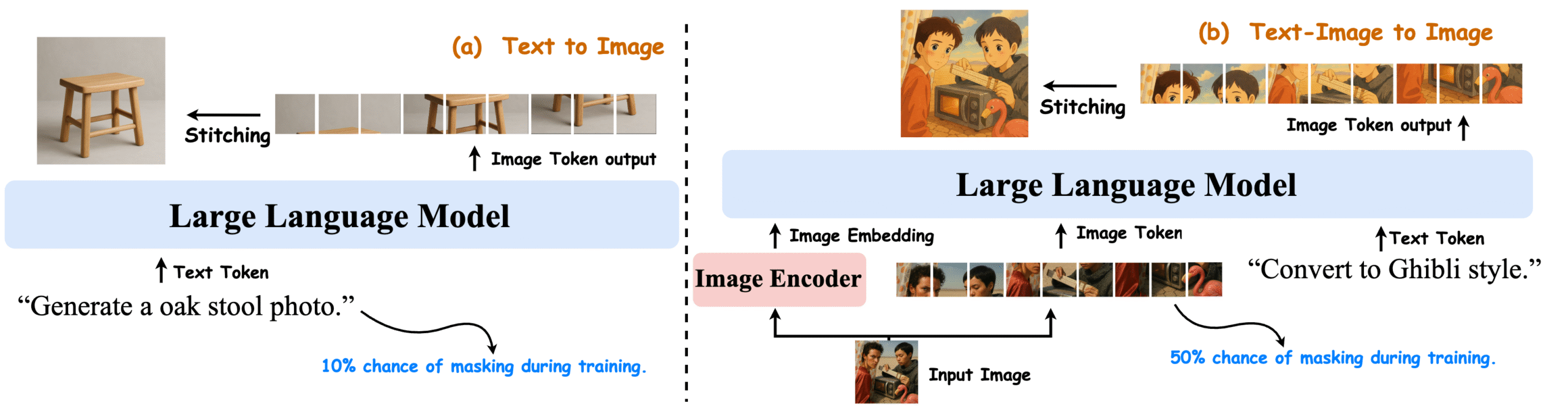
Janus-4o-7B Model Architecture
Janus-4o-7B is a multimodal large language model fine-tuned from Janus-Pro-7B using the ShareGPT-4o-Image dataset. It is designed to handle both text-to-image and text-and-image-to-image generation tasks. The model architecture includes:
- Text Encoder: Processes textual inputs to generate embeddings.
- Image Encoder: Utilizes vision transformers to encode image inputs into embeddings.
- Fusion Layer: Combines text and image embeddings to generate multimodal representations.
- Decoder: Generates outputs (images or textual descriptions) based on the fused embeddings.
This architecture enables the model to understand and generate multimodal content effectively.
🖥️ Hardware Requirements
For Training Janus-4o-7B
Training a model of this scale requires substantial computational resources:
- GPUs: Multiple high-performance GPUs, such as NVIDIA A100 or H100, are essential for parallel processing and efficient training.
- CPU: Multi-core processors (e.g., AMD Ryzen 9 or Intel Xeon) to handle data preprocessing and coordination tasks.
- RAM: At least 64GB of system memory to manage large datasets and model parameters.
- Storage: High-speed SSDs with a capacity of 1TB or more to store datasets and model checkpoints.
For Inference
For deploying the model for inference:
- GPU: A single high-performance GPU (e.g., NVIDIA RTX 3090 or equivalent) with sufficient VRAM (24GB or more) to load and run the model efficiently.
- CPU: A modern multi-core processor to handle inference requests.
- RAM: At least 32GB of system memory to support inference operations.
- Storage: SSD storage for fast model loading and data access.
These specifications ensure smooth and efficient inference operations.
🛠️ Software Requirements
Common Dependencies
Both training and inference processes require the following software:
- Operating System: Linux (Ubuntu 20.04 or higher) is recommended for compatibility with AI frameworks.
- Python: Version 3.8 or higher for running scripts and managing dependencies.
- CUDA Toolkit: Latest stable version to enable GPU acceleration.
- PyTorch: Framework for model development and training.
- Transformers Library: For handling model architectures and tokenization.
- Flask/Django: For serving the model via APIs in production environments.
- OpenAI API: For integrating GPT-4o functionalities.
These software components are essential for developing, training, and deploying multimodal models effectively.
🛠️ Installation Guide for ShareGPT-4o-Image
1. Obtain API Access
- Sign Up: Create an account on OpenAI.
- API Key: Navigate to the API section to generate your API key.
- Access Regions: If you’re in a region with access restrictions, consider using a proxy service like laozhang.ai to ensure stable connections.
2. Set Up Development Environment
- Python Installation: Ensure Python 3.8 or higher is installed
- Virtual Environment:
python -m venv gpt4o-env
source gpt4o-env/bin/activate # On Windows: gpt4o-env\Scripts\activate
- Install Dependencies:
pip install openai pillow numpy matplotlib
3. Configure API Key
- Set Environment Variable:
export OPENAI_API_KEY='your-api-key'
For Windows Command Prompt:
set OPENAI_API_KEY=your-api-key
4. Verify Installation
- Test Script:
import openai
openai.api_key = 'your-api-key'
response = openai.Image.create(
prompt="A futuristic cityscape at sunset",
n=1,
size="1024x1024"
)
print(response['data'][0]['url'])
This script should return a URL to the generated image.
🛠️ Installation Guide for Janus-4o-7B
1. Clone Repository
- Git Clone:
git clone https://github.com/TiancongLx/gpt-4o-image.git
cd gpt-4o-image
2. Install Dependencies
- Install pnpm:
npm install -g pnpm
- Install Project Dependencies:
pnpm install
3. Configure Environment Variables
- Copy Example File:
cp .env.example .env
- Edit
.envFile:
OPENAI_API_KEY=your-api-key
OPENAI_BASE_URL=https://api.openai.com/v1
GPT_4O_IMAGE_MODEL=gpt-4o-image
TIMEOUT_MINUTES=5
PROMPT_FILENAME=prompt.txt
OUTPUT_DIR=output/Playground
CONCURRENCY_NUM=1
HTTP_PROXY=http://127.0.0.1:1080
Ensure to replace your-api-key with your actual OpenAI API key.github.com+2blog.laozhang.ai+2cursor-ide.com+2
4. Generate Images
- Prepare Prompts: Create a
prompt.txtfile with your desired image descriptions.github.com - Run Image Generation:
tsx src/main.ts generate -n 5
This command generates 5 images concurrently based on the prompts in prompt.txt.github.com
💡 Tips for Effective Usage
- Be Specific in Prompts: Detailed prompts yield better results. For example, instead of “a cat”, use “a fluffy white cat sitting on a red velvet cushion”.
- Use Descriptive Language: Incorporate adjectives and adverbs to paint a vivid picture.
- Start Simple and Iterate: Begin with a basic prompt and refine it based on the results.
- Consider Negative Prompts: Specify elements you don’t want in the image, such as “no blurry background”.
- Experiment with Styles: Test different art styles, color schemes, and perspectives to achieve the desired outcome.
🔮 Future Work
- Unified Generation & Understanding Benchmarks
While ShareGPT‑4o‑Image and Janus‑4o demonstrate strong generation, GPT‑4o still falls short in fine-grained reasoning and instruction compliance. Future efforts should create benchmarks spanning diverse reasoning and generation scenarios to push models toward deeper multimodal unification. - Architectural Innovations for Precision
GPT‑4o occasionally struggles with spatial placement, textual accuracy, and detailed edits. Future generative models could integrate reasoning-aware architectures or hybrid mechanisms (e.g., early-/late-fusion, diffusion-autoregressive hybrids) to improve fidelity. - Scaling Janus‑4o with Expanded Modalities
ShareGPT‑4o‑Image currently focuses on text and image. Scaling to include audio, video, or interactive generation (similar to broader ShareGPT‑4o efforts) could unlock more robust multimodal capabilities . - Dataset Diversity & Subtlety
Expanding ShareGPT‑4o‑Image with more ambiguous or context-rich prompts will enable models to generalize better to complex instructions and rare scenarios.
✅ Conclusion
ShareGPT‑4o‑Image introduces a high-quality, large-scale dataset of 92K GPT‑4o-generated samples (45K text-to-image, 46K image-editing cases), enabling open-source multimodal models to approach GPT‑4o-level image generation. Janus‑4o‑7B, fine-tuned on this dataset, shows marked improvements in both text-to-image (80% GenEval accuracy) and image-to-image tasks (3.26 ImgEdit-Bench score) compared to Janus‑Pro .
While limitations in precise editing, spatial reasoning, and abstract instruction alignment remain, this work marks a meaningful step toward democratizing GPT‑4o-caliber multimodal generation within open frameworks.
📚 References
- Chen, J., Cai, Z., Chen, P., et al. (2025). ShareGPT‑4o‑Image: Aligning Multimodal Models with GPT‑4o‑Level Image Generation. arXiv:2506.18095 arxiv.org+15sharegpt4o.com+15github.com+15
- Ning Li, Jingran Zhang, Justin Cui (2025). Have we unified image generation and understanding yet? An empirical study of GPT‑4o’s image generation ability. arXiv:2504.08003 researchgate.net+2arxiv.org+2arxiv.org+2
- GPT‑4o‑Image Model. EmergentMind. Limitations & Research Directions emergentmind.com
- Xinjie Zhang et al. (2025). Unified Multimodal Understanding and Generation Models: Advances, Challenges, and Opportunities. arXiv:2505.02567 arxiv.org
- ShareGPT‑4o Dataset Info, GitHub. Comprehensive Multimodal Annotations with GPT‑4o sharegpt4o.github.io
- Janus‑Pro: Unified Multimodal Understanding and Generation with Scaling. arXiv:2501.17811 themoonlight.io+3arxiv.org+3reddit.com+3