🎯AnimateAnyMesh: Empowering Creators with Text-Driven 4D Mesh Animation

🧠 Introduction
AnimateAnyMesh is a pioneering framework that enables the generation of high-quality, temporally consistent 4D animations from arbitrary 3D meshes using natural language prompts. This innovation addresses the challenges of spatio-temporal modeling complexity and the scarcity of 4D training data, which have traditionally hindered the creation of dynamic 3D content.
🔧 Core Components
🧩 DyMeshVAE Architecture
At the heart of AnimateAnyMesh lies the DyMeshVAE, a variational autoencoder designed to efficiently compress and reconstruct dynamic mesh sequences. This architecture disentangles spatial and temporal features by decomposing meshes into initial frame vertices and relative trajectories, preserving local topological structures. The encoder utilizes distinct positional encoding for spatial and temporal components and incorporates mesh adjacency information to aggregate neighboring features, enhancing the model’s ability to handle complex mesh topologies.
🗣️ Shape-Guided Text-to-Trajectory Model
To facilitate text-driven animation, AnimateAnyMesh employs a Shape-Guided Text-to-Trajectory Model that generates trajectory features conditioned on both the initial mesh latent representation and text embeddings. This model is trained using a rectified flow-based strategy in the compressed latent space, enabling high-quality, text-conditional generation of mesh animations.
🗂️ DyMesh Dataset
AnimateAnyMesh is trained on the DyMesh Dataset, a comprehensive collection of over 4 million dynamic mesh sequences annotated with text descriptions. This extensive dataset provides diverse examples of mesh animations, enabling the model to learn a wide range of motion patterns and semantic associations between text prompts and 3D mesh movements.
🚀 Performance and Applications
Experimental results demonstrate that AnimateAnyMesh can generate semantically accurate and temporally coherent mesh animations within seconds, outperforming existing methods in both quality and efficiency. The framework supports meshes of arbitrary topology, making it versatile for various applications, including gaming, virtual reality, and digital content creation. Furthermore, AnimateAnyMesh facilitates the animation of generated 3D objects, broadening its applicability in creative industries.

🧑💻 Meet the Creators
AnimateAnyMesh was developed by a collaborative team of researchers from Huazhong University of Science and Technology, DAMO Academy at Alibaba Group, and Hupan Lab. Their combined expertise in computer vision, machine learning, and 3D graphics has led to the creation of this groundbreaking framework.
👨💻 Zijie Wu
Huazhong University of Science and Technology
Zijie Wu is a prominent researcher specializing in 3D vision and generative modeling. He has contributed to several innovative projects in the field of dynamic mesh generation and compression. His work on the DyMeshVAE architecture has been pivotal in enabling efficient 4D content creation.
👨💻 Chaohui Yu
DAMO Academy, Alibaba Group
Chaohui Yu focuses on integrating vision, language, and action in AI models. He has developed models like WorldVLA, which unify action and image understanding, and has contributed to advancements in text-guided 3D animation. His expertise bridges the gap between visual perception and action generation.
👨💻 Fan Wang
DAMO Academy, Alibaba Group
Fan Wang is known for his work in 3D graphics and deep learning. He has collaborated on projects like Animate3D and VCD-Texture, focusing on animating 3D models and synthesizing textures through AI. His contributions enhance the realism and efficiency of 3D content generation.
👨💻 Xiang Bai
Huazhong University of Science and Technology
Xiang Bai is a leading figure in visual computing and AI research. He has made significant contributions to 3D object detection and point cloud processing. His work on SC4D has advanced motion transfer and video-to-4D generation, influencing the development of dynamic 3D content.
Their collective efforts have resulted in AnimateAnyMesh, a pioneering framework that enables the generation of high-quality, temporally consistent 4D animations from arbitrary 3D meshes using natural language prompts. This innovation addresses the challenges of spatio-temporal modeling complexity and the scarcity of 4D training data, making 4D content creation more accessible and practical.
For more information and to explore the capabilities of AnimateAnyMesh, visit the official website: AnimateAnyMesh.
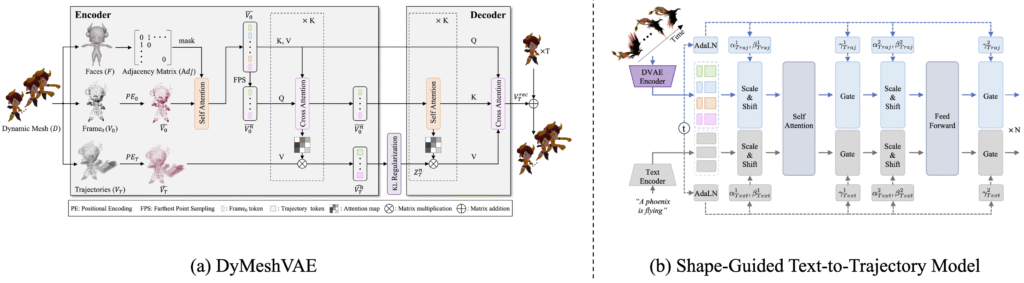
⚙️ Working Mechanism
AnimateAnyMesh leverages a feed-forward framework to transform text prompts into 4D animations for arbitrary 3D meshes. The core components include:
- DyMeshVAE Architecture: A variational autoencoder that compresses dynamic mesh sequences by disentangling spatial and temporal features while preserving local topological structures.
- Shape-Guided Text-to-Trajectory Model: Generates trajectory features conditioned on both the initial mesh latent representation and text embeddings, enabling high-quality, text-conditional generation of mesh animations.
This approach allows for the generation of semantically accurate and temporally coherent mesh animations in a few seconds, significantly outperforming existing methods in both quality and efficiency.
🔍 Comparison with Other Models
| Feature | AnimateAnyMesh | Other Models |
|---|---|---|
| Input Type | Text prompts | Varies (e.g., motion capture, keyframes) |
| Mesh Topology Flexibility | Arbitrary 3D meshes | Often limited to specific categories |
| Temporal Coherence | High | Varies |
| Training Data | DyMesh Dataset (over 4M sequences) | Varies |
| Generation Speed | Few seconds | Varies |
| Open Source Availability | Yes | Varies |
AnimateAnyMesh distinguishes itself by enabling text-driven animation of arbitrary 3D meshes, offering high temporal coherence and rapid generation, which are often challenging for other models.
📂 Open Source Details
AnimateAnyMesh is committed to openness and transparency. The authors have pledged to release all data, code, and models associated with the project. This includes the DyMesh Dataset, the DyMeshVAE architecture, and the Shape-Guided Text-to-Trajectory Model. By making these resources publicly available, the team aims to foster collaboration and further advancements in the field of 4D content creation.
💻 System Requirements
To run AnimateAnyMesh efficiently, the following system specifications are recommended:
- Operating System: Windows 10 64-bit or Linux
- Processor: Intel Core i7 or AMD Ryzen 7 (8 cores or more)
- Graphics Card: NVIDIA RTX 2070 or AMD Radeon RX 5700 XT (8GB VRAM or more)
- Memory: 32GB RAM or more
- Storage: SSD with at least 100GB free space
- Software: Python 3.8+, PyTorch 1.9+, CUDA 11.1+
These specifications ensure smooth processing and generation of high-quality 4D animations. However, performance may vary based on the complexity of the 3D meshes and the length of the animations
🚀 Future Work
AnimateAnyMesh has laid a solid foundation for text-driven 4D mesh animation. Future developments aim to:
- Enhance Temporal Coherence: Improving the consistency of animations over extended periods to ensure smoother transitions and more realistic movements.
- Expand Dataset Diversity: Incorporating a broader range of dynamic mesh sequences to train the model, enhancing its ability to generalize across different scenarios.
- Optimize Computational Efficiency: Reducing the computational resources required for generating animations, making the tool more accessible to users with varying hardware capabilities.
- Integrate Real-Time Animation Capabilities: Developing features that allow for real-time generation and manipulation of animations, facilitating interactive applications.
- Improve User Interface: Creating more intuitive interfaces for users to interact with the system, lowering the barrier to entry for non-expert users.
✅ Conclusion
AnimateAnyMesh represents a significant advancement in the field of 4D content creation. By enabling the generation of high-quality, temporally coherent mesh animations from natural language prompts, it democratizes the animation process, making it more accessible to creators across various industries. The combination of the DyMeshVAE architecture and the Shape-Guided Text-to-Trajectory Model offers a robust solution to the challenges of spatio-temporal modeling and data scarcity. As the model continues to evolve, it holds the potential to revolutionize animation workflows, offering new possibilities for storytelling, gaming, virtual reality, and beyond.
📚 References
- Wu, Z., Yu, C., Wang, F., & Bai, X. (2025). AnimateAnyMesh: A Feed-Forward 4D Foundation Model for Text-Driven Universal Mesh Animation. arXiv. Retrieved from arxiv.org/abs/2506.09982arxiv.org
- AnimateAnyMesh Official Website. Retrieved from animateanymesh.github.io/AnimateAnyMesh/animateanymesh.github.io
- Gat, I., Raab, S., Tevet, G., Reshef, Y., Bermano, A. H., & Cohen-Or, D. (2025). AnyTop: Character Animation Diffusion with Any Topology. arXiv. Retrieved from arxiv.org/abs/2502.17327arxiv.org
- Huang, X., Cheng, Y., Tang, Y., Li, X., Zhou, J., & Lu, J. (2023). Efficient Meshy Neural Fields for Animatable Human Avatars. arXiv. Retrieved from arxiv.org/abs/2303.12965arxiv.org
- Aberman, K., Li, P., Lischinski, D., Sorkine-Hornung, O., Cohen-Or, D., & Chen, B. (2020). Skeleton-Aware Networks for Deep Motion Retargeting. arXiv. Retrieved from arxiv.org/abs/2005.05732arxiv.org