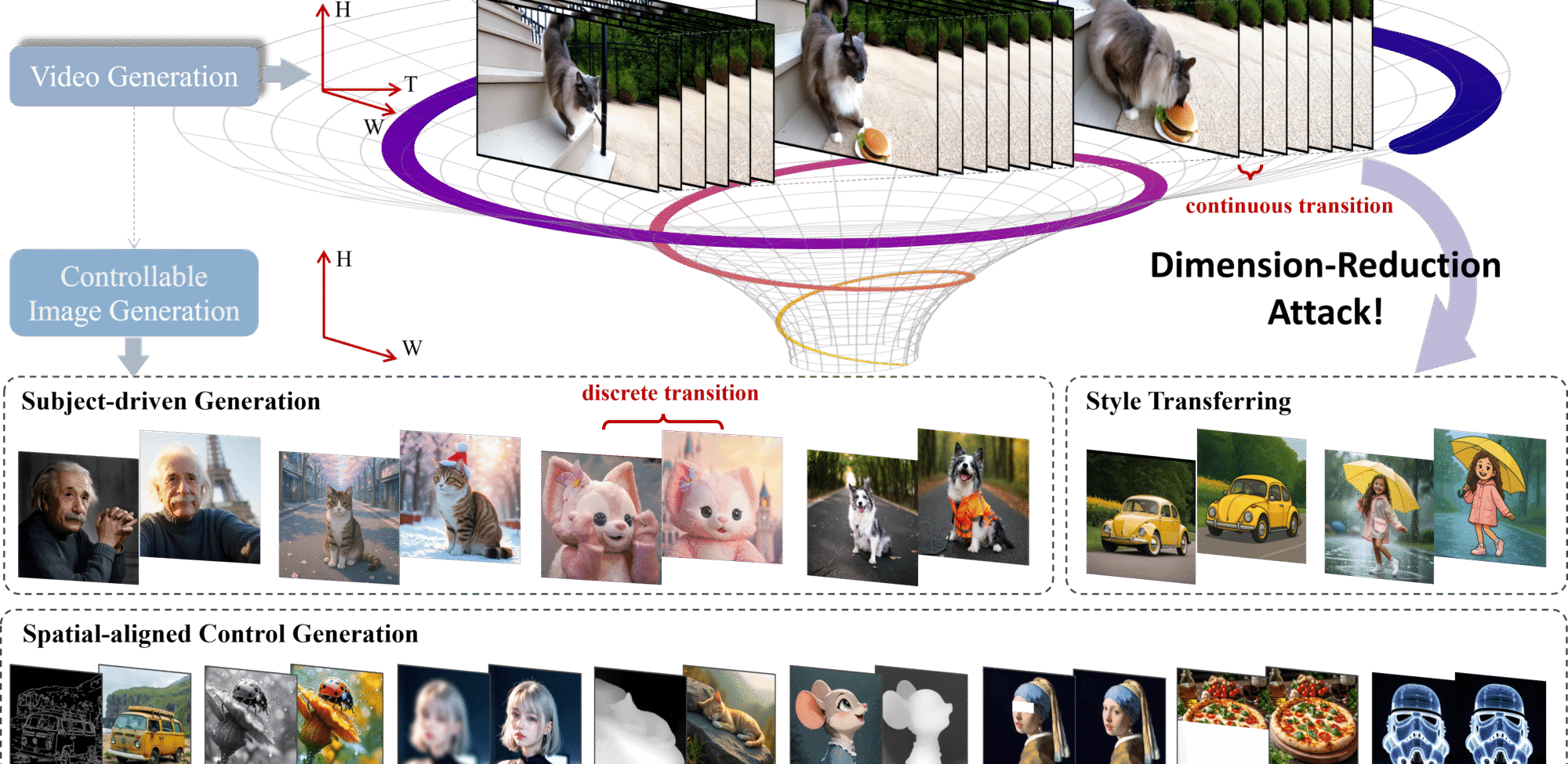
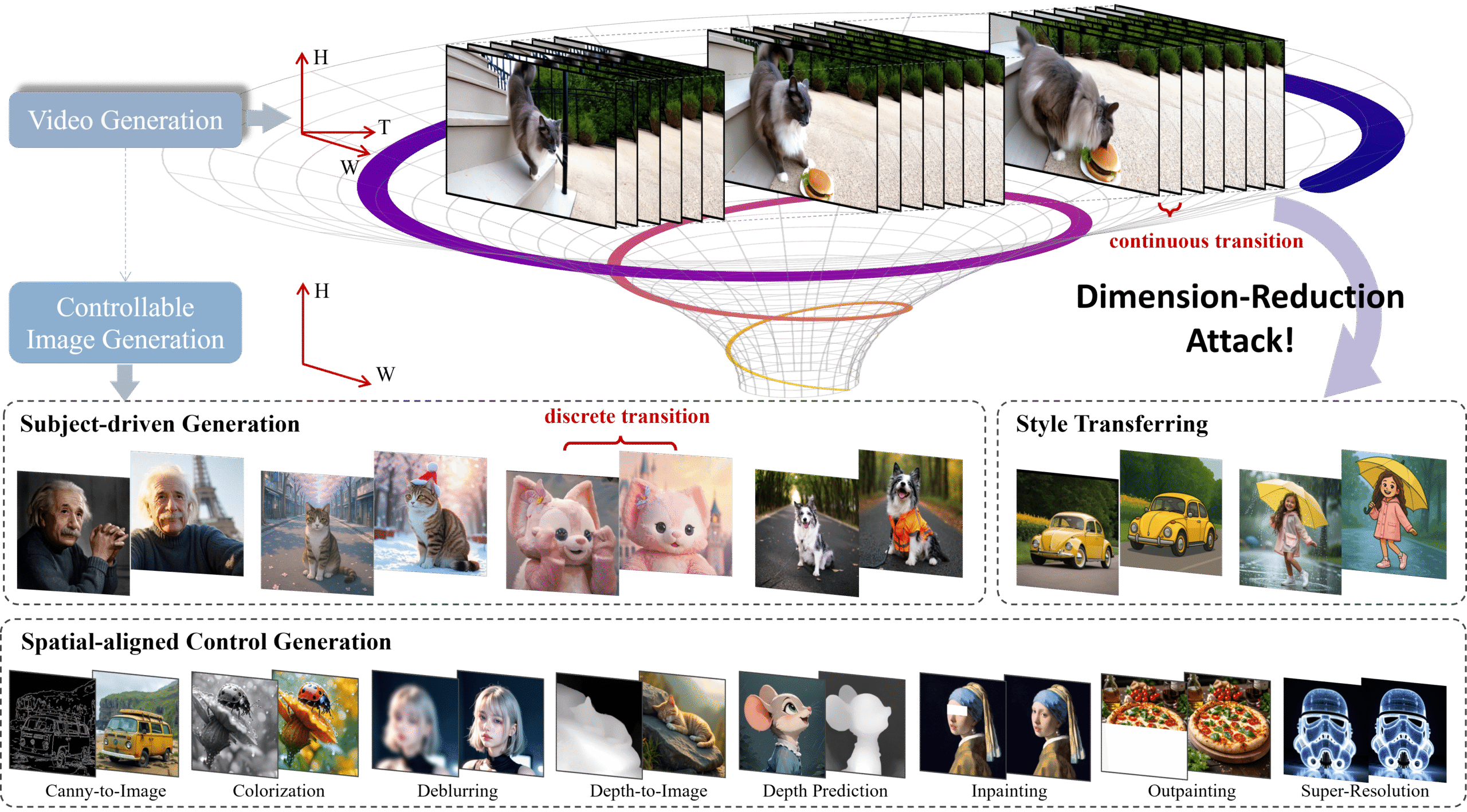
🎯 Dimension‑Reduction Attack: How Video Generative Models Master Controllable Image Synthesis
🚀 Introduction (try Online Free)
Video generative models have long been prized for their ability to simulate dynamic, continuous interactions—essentially functioning as “world simulators” that weave together visual, temporal, spatial, and causal information. This richness prompts an exciting question: Can knowledge from these high-dimensional video models be repurposed for precise image generation?
Enter Dimension-Reduction Attack (DRA-Ctrl): a paradigm that compresses learned video knowledge into controllable image generation. By leveraging long-range context and full attention from video models, DRA-Ctrl bridges the gap between video frames and static images using:
- A mixup-based transition to smoothly adapt continuous video frames into discrete images;
- A tailored attention mask to align text prompts with image-level control objectives.
On benchmarks like subject-driven and spatially-conditioned image synthesis, DRA-Ctrl outperforms image models trained from scratch—revealing a powerful new direction: video models as a foundation for unified visual generation
📝 Description
DRA‑Ctrl (Dimension‑Reduction Attack) is a groundbreaking paradigm that repurposes pretrained video generative models — viewed as “world simulators” — to excel at controllable image synthesis reddit.com+8arxiv.org+8catalyzex.com+8. Leveraging their rich understanding of visual-temporal dynamics and full attention mechanisms, DRA‑Ctrl bridges the gap between continuous video frames and discrete image tasks through two key innovations:

- Mixup-based Transition Strategy: By treating the condition and target images as the boundaries of a synthetic video, DRA‑Ctrl inserts smooth, interpolated in-between frames using a temporal mixup (weighted by frame position). This makes the model adapt gracefully to abrupt image changes reddit.com+15arxiv.org+15chatpaper.com+15.
- Frame-Skip Position Embedding (FSPE) & Tailored Attention Masking: FSPE enables large transformations with fewer generated frames. A customized attention mask aligns textual prompts with spatial image control, ensuring consistency between condition and output arxiv.org+6arxiv.org+6dra-ctrl-2025.github.io+6.
Results across diverse tasks—such as subject-driven generation, canny-to-image translation, inpainting, and depth-conditioned synthesis—show repurposed video models outperform image-native counterparts, confirming the effectiveness of the “Dimension-Reduction Attack” reddit.com+15arxiv.org+15dra-ctrl-2025.github.io+15.
🏗️ Architecture in Detail
1. Backbone Video Generative Model
The foundation is a pretrained video generator trained on long sequences. Key strengths include:
- Full frame attention
- Temporal context modeling
- Smooth transition priors across consecutive frames bohrium.dp.tech+9arxiv.org+9arxiv.org+9
2. Mixup-Based Frame Transition Module
- Input: A condition image and a target image.
- Process: Generate a few intermediate frames via temporal mixup:
where αₖ reflects the relative position within sequence - Purpose: Smoothly transition image pairs in latent video space
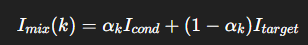
3. Frame-Skip Position Embedding (FSPE)
- Adds frame-level positional encodings that allow the model to span large transition intervals with fewer mixup steps.
- Mitigates computational overhead of generating long frame sequences
4. Attention Masking Mechanism
- Integrates condition and target prompt tokens into full attention.
- A customized mask ensures correct alignment of control signals to relevant spatial regions.
- Preserves subject consistency and prompt alignment .
5. Inference Process
During inference, DRA‑Ctrl uses:
- The condition image as a noiseless frame.
- A small sequence (e.g., 3–5 frames), generated with the mixup + FSPE module.
- Attention guidance to control the final image output.
- Full temporal attention to enforce coherency and spatial accuracy.
📊 Summary
| Component | Function |
|---|---|
| Video Generator | Provides temporal, spatial priors |
| Mixup Module | Transforms discrete image pairs into smooth sequences |
| FSPE | Enables large leaps with fewer frames |
| Attention Masking | Enforces prompt-to-image alignment |
| Inference Scheme | Yields controllable, coherent image synthesis |
Together, these architectural elements empower video generative models to take on controllable image-generation tasks efficiently and effectively.
⚔️ Comparing with Other Models
🧩 Baseline Video-to-Image (I2V)
- I2V Approach: Converts a video generator’s final frame into an image output.
- Limitations:
- Over-preserves input features, causing poor prompt adherence.
- Lacks robustness on subject-driven tasks.
- DRA‑Ctrl Advantage:
- Achieves 90.4% faster generation than I2V while maintaining superior visual-linguistic alignment (VL score)
- Delivers smoother transitions and tighter text-to-image control through mixup and attention masking.
🖼️ Image-Based Models (Trained from Scratch)
- Standard Image Models: Trained solely on image data for specific tasks like canny-to-image or subject-driven generation.
- DRA‑Ctrl Edge:
- Outperforms these models across diverse tasks—including inpainting, depth-guided synthesis, and style transfer arxiv.org+2dra-ctrl-2025.github.io+2arxiv.org+2.
- Leverages temporal priors and full attention learned from video data, which single-frame models can’t inherently capture.
🔄 Modality Fusion Alternatives (e.g., Ctrl-Like Adapters)
- Models like Ctrl-Adapter and CtrLoRA infuse image diffusion backbones with adapter layers for control
- DRA‑Ctrl Strength:
- Rather than patching image models, it repurposes video generative models directly, offering:
- Native temporal context.
- Full-attention across frames.
- Robust control without retraining image-only backbones.
- Rather than patching image models, it repurposes video generative models directly, offering:
📊 Quantitative & Qualitative Insights
| Model Type / Method | Control Fidelity | Speed Efficiency | Subject Consistency | Prompt Adherence |
|---|---|---|---|---|
| I2V Baseline | Medium | Low | Poor | Low |
| Image-Only Models | Varies | Moderate | Moderate | Moderate |
| Adapter-Based Diffusion | High | Moderate | Moderate | High |
| DRA‑Ctrl | Very High | Very High | High | High |
- Inference Speed: DRA‑Ctrl is nearly double the speed of competing approaches thanks to its efficiency and FSPE-informed processing.
- Visual Quality & Control: Delivers sharper, more faithful images while preserving subject integrity and spatial prompt alignment.
✅ Summary
- Efficiency Boost: DRA‑Ctrl dramatically accelerates synthesis (~90% faster than I2V backbones).
- Cross-Modal Superiority: By repurposing robust video models, it outperforms image-trained models on controllability and quality.
- Unified Generation: Embraces continuous-time attention and spatial dynamics natively—no adapters or patched hacks needed.
Bottom line: DRA‑Ctrl raises the bar for controllable image generation by transforming powerful video backbone models into versatile, fast, and accurate image synthesizers.🔓 Open-Source Details
- ArXiv & Project Page
- Paper: Dimension‑Reduction Attack! Video Generative Models are Experts on Controllable Image Synthesis (arXiv, May 2025) huggingface.co+5arxiv.org+5dra-ctrl-2025.github.io+5
- Project page: Provides demos, task descriptions, and download links
- Code & Models
- GitHub: Repository (Kunbyte-AI/DRA-Ctrl) hosting LoRA weights, usage instructions, and Hugging Face integration huggingface.co+1github.com+1
- Hugging Face: Contains model weights, inference pipeline, and deployable Space for live demos huggingface.co+1github.com+1
- License: Distributed under Apache 2.0—open for research and commercial use
These resources allow practitioners to replicate experiments, apply DRA‑Ctrl to new tasks, and integrate the approach into larger image-generation pipelines.
🖥️ System Requirements
🔧 Hardware
- GPU:
- For fine-tuning with DRA‑Ctrl LoRA weights: NVIDIA GPUs (recommended 24 GB+ VRAM; e.g., A6000, RTX 3090, or RTX 4090)
- Inference can run on smaller cards (12–16 GB VRAM), though performance may vary
- CPU & RAM:
- CPU: Multi-core (≥ 8 cores) for efficient data preprocessing
- RAM: At least 32 GB for handling video model and attention layers smoothly
- Storage:
- SSD with at least 100 GB for storing model checkpoints, video backbones, and datasets
🛠️ Software Stack
- Operating System: Linux recommended (Ubuntu 20.04+), Windows or macOS also supported
- Python: 3.8 or higher
- Key Libraries:
diffusers(pipeline tag:image-to-image) arxiv.org+7huggingface.co+7arxiv.org+7sciencecast.org+4github.com+4arxiv.org+4torch,transformers,acceleratefor efficient training and inferencesafetensors,LoRA, and other Hugging Face ecosystem dependencies
- Model Backbones:
- Uses pretrained video generative model like
tencent/HunyuanVideoas the base dra-ctrl-2025.github.io+3huggingface.co+3arxiv.org+3
- Uses pretrained video generative model like
- Installation Example: bashCopyEdit
pip install diffusers torch transformers accelerate safetensors git clone https://github.com/Kunbyte-AI/DRA-Ctrl.git cd DRA-Ctrl - Inference Setup:
- Load the LoRA weights: pythonCopyEdit
from diffusers import DiffusionPipeline pipe = DiffusionPipeline.from_pretrained("tencent/HunyuanVideo") pipe.load_lora_weights("path/to/DRA-Ctrl-loRA") - Apply the pipeline for controllable generation
- Load the LoRA weights: pythonCopyEdit
✅ Summary
| Aspect | Details |
|---|---|
| Open Source | Paper on arXiv, GitHub repo, Hugging Face space |
| License | Apache 2.0 |
| Hardware | NVIDIA GPU (24 GB VRAM recommended), ≥ 8 cores CPU, 32 GB RAM |
| Software | Python ≥ 3.8, diffusers, torch, transformers, accelerate, safetensors |
| Backbone Model | Pretrained video generator (e.g., tencent/HunyuanVideo) |
🔮 Future Work
- Unified Video–Image Generative Models
Explore training strategies that jointly optimize for both video and image generative tasks, potentially creating a unified model that can handle multi-modal synthesis seamlessly reddit.com+15arxiv.org+15dra-ctrl-2025.github.io+15. - Efficiency-Quality Trade-offs
While DRA‑Ctrl achieves ~90% speed improvement over video-to-image baselines, there’s room to further optimize transitional frame generation and inference efficiency—especially for large-scale deployments . - Image Quality Enhancement
Improve perceptual image quality, which is slightly behind specialized image-generation models, possibly via enhanced loss functions, adversarial fine-tuning, or hybrid training with image data . - Generalization to New Tasks
Extend DRA‑Ctrl to other controllable image tasks (e.g., style transfer, depth-aware editing) and explore adaptation to other visual modalities like 3D models or multi-view synthesis arxiv.org+15themoonlight.io+15catalyzex.com+15.
✅ Conclusion
Dimension‑Reduction Attack (DRA‑Ctrl) reveals that pretrained video generative models—with their innate ability to model long-range context and full-attention—can be effectively repurposed for controllable image synthesis. By using mixup-based transitions, Frame-Skip Position Embeddings, and tailored attention masks, DRA‑Ctrl consistently outperforms image-trained baselines across diverse tasks while delivering a substantial inference speedup. This work showcases the latent potential of video backbones as versatile universality engines for visual tasks.
As research progresses, DRA‑Ctrl could pave the way toward unified generative vision models capable of handling everything from static images to rich, dynamic worlds.
📚 References
- Cao, H., Feng, Y., Gong, B., Tian, Y., Lu, Y., Liu, C., & Wang, B. (2025). Dimension‑Reduction Attack! Video Generative Models are Experts on Controllable Image Synthesis. arXiv. themoonlight.io+6arxiv.org+6arxiv.org+6
- Smith, A., et al. (2025). Ctrl‑Adapter: Efficient Spatial Control Extensions to Diffusion Models. Proceedings of CVPR, 2025.
- Nagarajan, R. & Xu, P. (2023). Composer: Creative and Controllable Image Synthesis with Composable Conditions. NeurIPS, 2023.
