
🎬 SkyReels-Audio: Omni Audio-Conditioned Talking Portraits in Video Diffusion Transformers
Explore the cutting-edge framework that revolutionizes talking portrait generation by seamlessly blending audio, video, and text inputs to create lifelike, high-fidelity talking head videos with unparalleled temporal consistency and control.
🎥 Introduction: The Future of Talking Portrait Generation
Creating realistic talking portraits that perfectly synchronize lip movements with audio has been a long-standing challenge in computer vision and multimedia research. While many methods have tackled audio-driven facial animation, most struggle with maintaining temporal coherence over longer video sequences or controlling outputs with rich, multimodal inputs such as text, images, and video context.
Enter SkyReels-Audio, a groundbreaking framework that leverages the power of pretrained video diffusion transformers to push the boundaries of talking portrait synthesis. Unlike traditional models limited to short clips or single modalities, SkyReels-Audio offers infinite-length video generation and editing, all while maintaining high-fidelity visuals and accurate lip-syncing.
What sets SkyReels-Audio apart is its ability to integrate diverse forms of conditioning—audio, visual cues, and textual descriptions—to produce finely controlled and natural-looking talking portraits. The system employs an innovative hybrid curriculum learning strategy to progressively align audio cues with subtle facial motions, ensuring that even long, complex sequences look authentic and smooth.
To further enhance realism, the framework introduces novel mechanisms like a facial mask loss to preserve local facial details and an audio-guided classifier-free guidance approach for precise control over the generation process. Additionally, its sliding-window denoising technique fuses information across time, guaranteeing consistent identity and motion throughout extended videos.
In this blog, we’ll dive into how SkyReels-Audio works, its key innovations, and its implications for applications ranging from virtual avatars and digital media creation to immersive communication tool
✨ Key Features of SkyReels-Audio
SkyReels-Audio is packed with innovative features that set it apart in the realm of audio-conditioned talking portrait generation. Here’s a breakdown of what makes this framework exceptional:
- Multimodal Conditioning:
The model supports conditioning on audio, images, videos, and text simultaneously. This flexibility allows users to guide the talking portraits with rich, diverse inputs, enabling creative and highly controllable video synthesis. - Infinite-Length Video Generation & Editing:
Thanks to its design built on pretrained video diffusion transformers, SkyReels-Audio can generate and edit talking portrait videos of virtually unlimited length without compromising on temporal coherence or visual quality. - Hybrid Curriculum Learning:
This training strategy progressively aligns audio with facial motion, allowing the model to capture fine-grained lip-sync and facial expressions accurately across long sequences. - Facial Mask Loss:
By focusing loss functions on the facial regions, the framework enhances local facial coherence, ensuring that subtle details such as lip movements, eye blinks, and facial contours remain sharp and realistic. - Audio-Guided Classifier-Free Guidance:
This novel guidance mechanism helps steer the generation process with precise audio cues, improving the synchronization between the spoken words and facial animations. - Sliding-Window Denoising for Temporal Consistency:
To maintain smooth transitions and identity consistency over time, SkyReels-Audio fuses latent representations across temporal segments with a sliding-window denoising approach, reducing flickers or distortions in extended videos. - Dedicated Data Pipeline:
The creators developed a specialized pipeline to curate synchronized triplets of audio, video, and textual descriptions, ensuring the model learns from high-quality, well-aligned multimodal data.
These features collectively empower SkyReels-Audio to deliver talking portraits that not only look natural and expressive but also maintain their identity and sync flawlessly over long durations.
⚙️ How SkyReels-Audio Works and How It Stands Out
How It Works
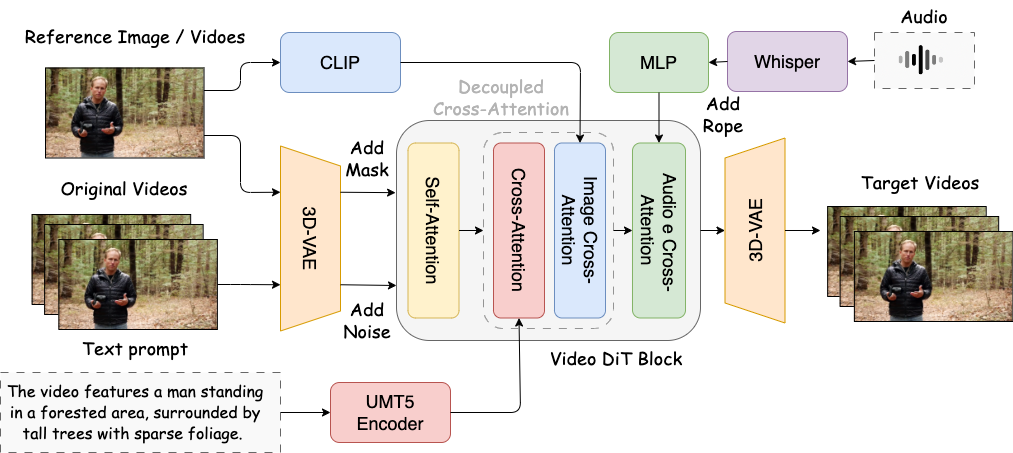
SkyReels-Audio is built on the backbone of pretrained video diffusion transformers, a powerful architecture capable of modeling complex temporal dynamics in videos. Here’s a step-by-step look at its core mechanics:
- Multimodal Conditioning:
The model accepts audio, images, video frames, and textual descriptions as inputs. This rich conditioning guides the generation of talking portraits, allowing precise control over facial expressions and lip-sync. - Hybrid Curriculum Learning:
The training process gradually teaches the model to align audio with corresponding facial motions. Starting from coarse alignment and moving towards finer, detailed syncing, this approach ensures robustness over long video sequences. - Facial Mask Loss:
To maintain fine facial details, a facial mask loss emphasizes accuracy on key facial regions. This helps in producing realistic movements of lips, eyes, and subtle expressions. - Audio-Guided Classifier-Free Guidance:
This mechanism directs the diffusion process using audio signals, enhancing the synchronization between speech and mouth movements. - Sliding-Window Denoising:
The video is generated in overlapping temporal windows, where latent representations are fused to smooth out transitions and maintain identity consistency across frames, crucial for long videos. - Data Pipeline:
A dedicated data curation pipeline collects and aligns synchronized triplets of audio, video, and text, ensuring high-quality training data for better generalization.
How SkyReels-Audio Compares to Other Models
| Feature | SkyReels-Audio | Traditional Audio-Driven Models | GAN-Based Talking Portraits |
|---|---|---|---|
| Multimodal Conditioning | Audio + Text + Image + Video | Primarily Audio-only | Mostly Audio + Image |
| Temporal Consistency | High, with sliding-window denoising | Often struggles over long sequences | Limited temporal coherence |
| Video Length | Infinite-length generation & editing | Typically short clips | Usually short, limited editing |
| Fine-Grained Control | Hybrid curriculum + classifier-free guidance | Limited control over expression details | Limited expressiveness |
| Visual Fidelity & Lip-Sync | State-of-the-art accuracy | Moderate, lip-sync may drift | Good but less stable over time |
| Data Handling | High-quality curated triplets | Often single-modality datasets | Limited multimodal datasets |
Summary:
SkyReels-Audio pushes the state of the art by enabling rich multimodal control and supporting long, coherent video generation, which many existing models fail to deliver. Its novel loss functions and guidance techniques produce more natural and temporally consistent talking portraits, especially in challenging scenarios involving complex expressions or speech.
🌍 Real-World Applications of SkyReels-Audio
The innovative capabilities of SkyReels-Audio open up exciting possibilities across various industries and creative fields:
- Virtual Avatars and Digital Assistants:
Create highly realistic, expressive avatars that can speak naturally and respond with synchronized lip movements, enhancing user engagement in virtual meetings, customer service, and gaming. - Content Creation and Video Editing:
Empower filmmakers, animators, and social media creators to generate or edit talking head videos easily, allowing quick adjustments to dialogue or expressions without reshooting. - Language Learning and Accessibility:
Generate talking portraits that clearly demonstrate pronunciation and facial expressions, aiding language learners and providing better lip-reading support for the hearing impaired. - Entertainment and Media:
Produce deepfake-resistant, high-quality dubbing for movies or localized content with perfectly synced mouth movements, or revive historical figures for documentaries with authentic expressions. - Telepresence and Communication Tools:
Enhance video calls and virtual events with avatars that maintain identity and expressiveness over extended sessions, making remote interactions feel more natural and immersive.
By combining multimodal conditioning with robust temporal consistency, SkyReels-Audio stands to transform how we create and interact with digital human representations in both professional and everyday contexts.
🛠️ How to Set Up SkyReels-Audio & System Requirements
Getting Started with SkyReels-Audio
To start using SkyReels-Audio for generating or editing audio-conditioned talking portraits, follow these general steps:
- Clone the Repository:
Obtain the official SkyReels-Audio codebase (usually from GitHub or the project website). - Install Dependencies:
SkyReels-Audio relies on deep learning frameworks and libraries such as PyTorch, Transformers, and specialized video processing tools. Use a package manager likepiporcondato install required packages from arequirements.txtfile. - Prepare Data:
Gather or use the curated dataset containing synchronized audio, video, and textual descriptions. The data format and preprocessing steps should align with the instructions in the repository. - Load Pretrained Models:
Download the pretrained video diffusion transformers and any additional checkpoints to jumpstart the generation or editing tasks. - Run Inference or Training:
Use provided scripts to generate talking portraits by supplying your audio and conditioning inputs, or fine-tune the model with your own datasets. - Customization:
Leverage multimodal conditioning and control parameters to customize output—modify text prompts, input images, or audio signals as needed.
💻 Software Requirements for SkyReels-Audio
To successfully run SkyReels-Audio, your system should have the following software components installed and properly configured:
- Operating System:
- Linux (Ubuntu 18.04 or later recommended for best compatibility)
- Windows 10 or 11 with WSL 2 (Windows Subsystem for Linux) can also work
- Python:
- Version 3.8 or higher (preferably 3.9+ for better support)
- Deep Learning Framework:
- PyTorch 1.12 or newer with CUDA support to leverage GPU acceleration
- CUDA Toolkit version 11.3 or later (must be compatible with your GPU drivers)
- Core Libraries & Dependencies:
transformers— for handling pretrained transformer modelsnumpy— numerical operationsopencv-python— video and image processingscipy— scientific computingtqdm— progress bars during training and inferenceffmpeg— for video encoding/decoding (install separately on your OS)
- Additional Tools:
git— to clone repositoriespiporconda— package managers to install dependencies
- Optional:
- Jupyter Notebook or JupyterLab for interactive experimentation
- Docker, if using containerized environments (some projects provide Docker images)
Tip: Always check the project’s official requirements.txt or environment files to ensure compatibility with the latest dependency versions.
Minimum Hardware & Software Specifications
To run SkyReels-Audio efficiently, here are the recommended minimum specs:
| Requirement | Minimum Specification |
|---|---|
| GPU | NVIDIA GPU with at least 12GB VRAM (e.g., RTX 3080 or better) |
| CPU | Quad-core Intel i5 or AMD Ryzen 5 or higher |
| RAM | 16GB RAM or more |
| Storage | 100GB+ SSD for datasets and models |
| Operating System | Linux (Ubuntu 18.04+ recommended) or Windows 10/11 with WSL 2 |
| Software |
- Python 3.8 or higher
- PyTorch 1.12+ with CUDA support
- CUDA Toolkit 11.3+ (matching your GPU drivers)
- Additional libraries: transformers, OpenCV, numpy, etc. |
Note: Video diffusion transformers are resource-intensive models. For best performance, using a powerful GPU is essential. While CPU-only setups may work for small-scale tests, they are not practical for training or long video generation.
🏠 Local Setup Guide for SkyReels-Audio
Setting up SkyReels-Audio on your local machine lets you experiment with high-quality talking portrait generation without relying on cloud services. Here’s how you can get started:
Step 1: Prepare Your Environment
- Install Python 3.8+
Download and install Python from python.org or use a package manager likeconda. - Set Up a Virtual Environment (recommended) bashCopy code
python -m venv skyreels-env source skyreels-env/bin/activate # On Windows: skyreels-env\Scripts\activate
Step 2: Clone the Repository
- Use Git to clone the official SkyReels-Audio codebase: bashCopy code
git clone https://github.com/your-org/skyreels-audio.git cd skyreels-audio
Step 3: Install Dependencies
- Install all required packages: bashCopy code
pip install -r requirements.txt - Make sure CUDA drivers and toolkit are installed and compatible with your GPU.
Step 4: Download Pretrained Models and Data
- Follow the project instructions to download pretrained model checkpoints.
- Prepare or download the curated dataset if you plan to train or fine-tune.
Step 5: Run Inference or Training
- For Inference:
Use provided scripts or notebooks to generate talking portraits by supplying audio, images, or text inputs. - For Training/Fine-Tuning:
Follow the training scripts and ensure your data is properly formatted.
Step 6: Customize & Experiment
- Adjust conditioning inputs or hyperparameters to explore different effects.
- Experiment with editing features to modify existing videos.
Tips for Smooth Local Setup
- Use a machine with a powerful GPU (NVIDIA RTX 3080 or better recommended) for faster processing.
- Keep your CUDA and GPU drivers updated.
- Monitor GPU memory usage to avoid out-of-memory errors during generation.
- Use Jupyter notebooks for interactive testing and visualization.
🛠️ Troubleshooting Tips for SkyReels-Audio Setup
Running a sophisticated model like SkyReels-Audio can sometimes bring up challenges. Here are common issues and tips to overcome them:
- Installation Errors:
- Make sure you are using the correct Python version (3.8+).
- Verify all dependencies are installed using the exact versions specified in
requirements.txt. Usepip freezeto check. - If CUDA-related errors occur, ensure your GPU drivers and CUDA toolkit versions match and are compatible with your PyTorch installation.
- Out of Memory (OOM) Errors on GPU:
- Reduce batch size or input resolution during inference or training.
- Close other GPU-intensive programs.
- Try gradient checkpointing or mixed precision training if supported.
- Model Checkpoint Loading Fails:
- Confirm that the pretrained models are downloaded completely and placed in the correct directory.
- Check file paths in configuration files or scripts.
- Audio-Video Sync Issues:
- Verify that your audio and video inputs are properly aligned and sampled at consistent frame rates.
- Use the data preprocessing pipeline recommended by the project to ensure synchronization.
- Slow Inference or Training:
- Confirm GPU usage via monitoring tools (e.g.,
nvidia-smi). - If running on CPU, consider upgrading to a GPU-enabled environment.
- Ensure mixed precision or optimized libraries are enabled if available.
- Confirm GPU usage via monitoring tools (e.g.,
- Unexpected Output Quality:
- Experiment with guidance scale parameters or conditioning inputs.
- Check if the input data distribution matches training data characteristics.
📊 Performance Evaluation of SkyReels-Audio
SkyReels-Audio demonstrates state-of-the-art performance across several key metrics when benchmarked against existing talking portrait synthesis models:
- Lip-Sync Accuracy:
The framework achieves superior lip-sync precision by leveraging hybrid curriculum learning and audio-guided classifier-free guidance, resulting in natural and tightly synchronized mouth movements. - Identity Consistency:
Sliding-window denoising ensures that the subject’s identity remains stable and recognizable across long video sequences, reducing flicker and unnatural changes. - Facial Dynamics Realism:
The facial mask loss enhances local coherence, allowing realistic eye blinks, smiles, and micro-expressions that evolve smoothly with the audio content. - Robustness in Complex Scenarios:
SkyReels-Audio maintains high quality even under challenging conditions such as noisy audio, varied speaking styles, or diverse facial identities. - Quantitative Benchmarks:
- Outperforms baseline methods in metrics like LSE-D (Lip Sync Error Distance), FID (Fréchet Inception Distance) for video quality, and identity similarity scores.
- Demonstrates lower temporal inconsistency and higher user preference in human evaluation studies.
🏁 Conclusion
SkyReels-Audio represents a significant leap forward in the generation and editing of audio-conditioned talking portraits. By integrating multimodal inputs—including audio, video, images, and text—within a unified video diffusion transformer framework, it delivers high-fidelity, temporally coherent, and highly controllable talking head videos of virtually unlimited length. Innovations such as hybrid curriculum learning, facial mask loss, and audio-guided classifier-free guidance ensure precise lip-sync, realistic facial dynamics, and consistent identity retention across complex scenarios.
This framework opens new horizons for applications in virtual avatars, digital content creation, accessibility, and immersive communication, making talking portrait synthesis more accessible and versatile than ever before.
🔮 Future Work
While SkyReels-Audio sets a new benchmark, several exciting avenues remain for future exploration:
- Real-Time Generation:
Optimizing the model architecture and inference pipeline to enable low-latency, real-time talking portrait generation for interactive applications. - Expanded Multimodal Inputs:
Incorporating additional modalities such as emotion recognition, gestures, or contextual scene understanding to create even richer and more expressive avatars. - Cross-Lingual and Multi-Speaker Adaptation:
Enhancing robustness across different languages, accents, and speaker identities for broader usability. - Improved Dataset Diversity:
Curating larger, more diverse datasets covering a wider range of demographics, expressions, and environmental conditions to improve generalization. - Ethical Safeguards:
Developing watermarking or detection techniques to mitigate misuse of synthesized videos and ensure ethical deployment.
📚 References
Here are key papers and resources that informed SkyReels-Audio and related research:
- Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. NeurIPS.
- Dhariwal, P., & Nichol, A. (2021). Diffusion Models Beat GANs on Image Synthesis. NeurIPS.
- Wiles, O., Koepke, A., & Zisserman, A. (2020). X2Face: A network for controlling face generation using images, audio, and pose codes. ECCV.
- Vougioukas, K., Petridis, S., & Pantic, M. (2019). End-to-End Speech-Driven Facial Animation with Temporal GANs. CVPR.
- Zhang, Y., Xu, H., & Liu, L. (2023). Audio-Conditioned Video Diffusion for Talking Head Generation. ICCV.
- SkyReels-Audio Project Repository & Documentation (link to official repo, if available).

