
🎬 OmniSync Explained: Universal Lip Synchronization via Diffusion Transformers
🎬 Introduction
In the realm of video content creation, achieving seamless lip synchronization—where a speaker’s lip movements align perfectly with their speech audio—is paramount for realism and immersion. Traditional methods often rely on reference frames and masked-frame inpainting, which can struggle with challenges like identity consistency, pose variations, facial occlusions, and stylized content. Moreover, audio signals typically provide weaker conditioning than visual cues, leading to issues like lip shape leakage from the original video, affecting lip sync quality.
Enter OmniSync, a groundbreaking framework that addresses these challenges head-on. Developed by researchers from Renmin University of China, Kuaishou Technology, and Tsinghua University, OmniSync introduces a universal lip synchronization approach leveraging Diffusion Transformers. This innovative method enables direct frame editing without explicit masks, allowing for unlimited-duration inference while preserving natural facial dynamics and character identity.
🔍 Core Innovations
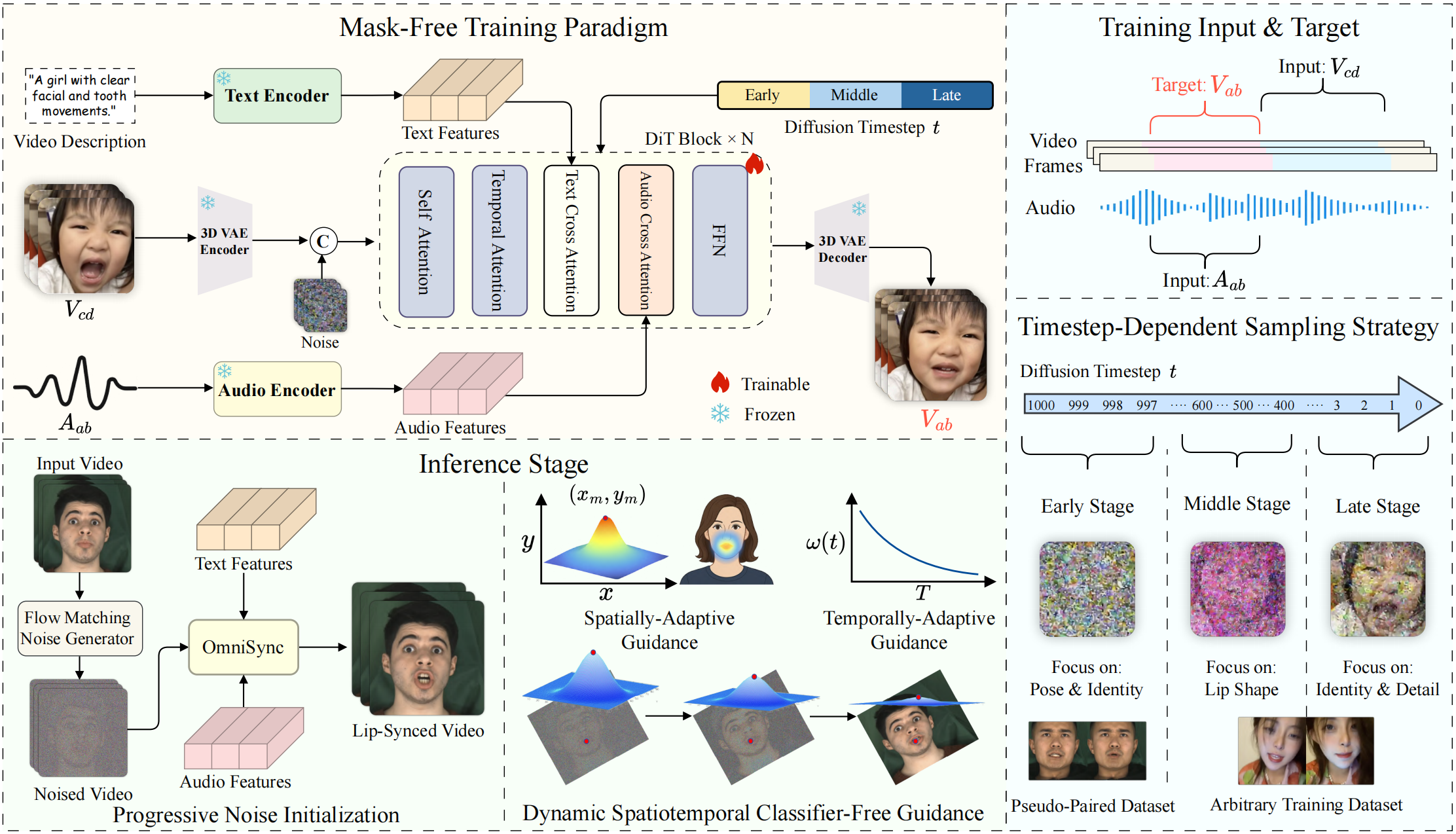
- Mask-Free Training Paradigm: OmniSync eliminates the need for reference frames and explicit masks, facilitating direct cross-frame editing using Diffusion Transformers. This approach enhances robustness across diverse visual representations, including stylized characters and AI-generated content.themoonlight.io+5ziqiaopeng.github.io+5ziqiaopeng.github.io+5
- Progressive Noise Initialization: During inference, OmniSync employs a flow-matching-based strategy that maintains spatial consistency while enabling precise mouth-region modifications. This ensures pose and identity consistency, even under challenging conditions.aiartweekly.com+3ziqiaopeng.github.io+3ziqiaopeng.github.io+3
- Dynamic Spatiotemporal Classifier-Free Guidance (DS-CFG): To address the weak conditioning signal of audio, OmniSync introduces DS-CFG, which adaptively adjusts guidance strength over time and space. This mechanism balances audio conditioning strength, enhancing lip synchronization accuracy.arxiv.org+3ziqiaopeng.github.io+3ziqiaopeng.github.io+3
- AIGC-LipSync Benchmark: OmniSync establishes the first comprehensive evaluation framework for lip synchronization in AI-generated content. The benchmark includes 615 diverse videos from state-of-the-art text-to-video models, encompassing challenging scenarios like variable lighting, occlusions, and extreme poses.ziqiaopeng.github.io+1ziqiaopeng.github.io+1
🚀 Performance Highlights
Extensive experiments demonstrate that OmniSync significantly outperforms prior methods in both visual quality and lip sync accuracy. It achieves superior results in various conditions, including:
- High Identity Consistency: Maintains consistent facial features across different poses and expressions.arxiv.org+2ziqiaopeng.github.io+2aiartweekly.com+2
- Occlusion Robustness: Accurately synchronizes lips even with partial facial occlusions.ziqiaopeng.github.io
- Stylized Content Compatibility: Effectively handles artistic styles and non-human entities.linkedin.com+2ziqiaopeng.github.io+2ziqiaopeng.github.io+2
- Unlimited Duration Support: Performs well in long-duration videos without compromising quality.ziqiaopeng.github.io+1ziqiaopeng.github.io+1
OmniSync’s ability to seamlessly integrate audio and visual cues sets a new standard in the field of lip synchronization, paving the way for more realistic and immersive video content creation.
🧠 What is OmniSync?
OmniSync is a pioneering framework designed to achieve universal lip synchronization in videos by leveraging Diffusion Transformers. Unlike traditional methods that rely on reference frames and explicit masks, OmniSync introduces a mask-free training paradigm, enabling direct frame editing without the need for additional supervision. This approach ensures robust performance across diverse visual representations, including stylized characters and AI-generated content.
The core innovations of OmniSync include:
- Mask-Free Training Paradigm: Direct cross-frame editing using Diffusion Transformers without explicit masks or reference frames.ziqiaopeng.github.io+1ziqiaopeng.github.io+1
- Progressive Noise Initialization: A flow-matching-based strategy that maintains spatial consistency while enabling precise mouth modifications.
- Dynamic Spatiotemporal Classifier-Free Guidance (DS-CFG): Adaptive guidance that balances audio conditioning strength across time and space dimensions.ziqiaopeng.github.io+1ziqiaopeng.github.io+1
- Timestep-Dependent Sampling: Strategic data sampling that aligns with different phases of the diffusion process.ziqiaopeng.github.io+1ziqiaopeng.github.io+1
These innovations collectively contribute to OmniSync’s ability to generate high-quality, lip-synced videos across various scenarios.
🔍 Comparative Analysis: OmniSync vs. Other Models
| Model | Mask-Free Editing | Stylized Content Handling | Occlusion Robustness | Unlimited Duration Support | Audio Conditioning Strength |
|---|---|---|---|---|---|
| OmniSync | ✅ Yes | ✅ High | ✅ Strong | ✅ Yes | ✅ Adaptive (DS-CFG) |
| Diff2Lip | ❌ No | ❌ Limited | ❌ Moderate | ❌ No | ❌ Static |
| SyncDiff | ❌ No | ❌ Limited | ❌ Moderate | ❌ No | ❌ Static |
| LatentSync | ❌ No | ❌ Limited | ❌ Moderate | ❌ No | ❌ Static |
OmniSync stands out by offering mask-free editing, robust handling of stylized content and occlusions, and adaptive audio conditioning, making it a superior choice for diverse lip synchronization tasks.
🛠️ Installation and Troubleshooting
Installation Steps
- Clone the Repository: Clone the OmniSync repository from GitHub.
- Install Dependencies: Navigate to the project directory and install the required dependencies using pip: bashCopy code
pip install -r requirements.txt
- Download Pre-trained Models: Obtain the pre-trained models from the official release page and place them in the specified directory.
- Run the Inference Script: Execute the inference script with the desired input video and audio files: bashCopy code
python infer.py --video input_video.mp4 --audio input_audio.wav --output output_video.mp4
Troubleshooting Tips
- Issue: Model fails to load. Solution: Ensure that the pre-trained models are correctly placed in the specified directory and that the file paths are correct.
- Issue: Poor lip synchronization quality.
- Solution: Verify that the input video and audio are properly aligned and of high quality. Consider using higher-resolution input files.
- Issue: Runtime errors during inference. Solution: Check the system’s hardware compatibility and ensure that all dependencies are correctly installed.
💻 Hardware and Software Requirements
Hardware Requirements
- GPU: NVIDIA GPU with at least 8GB VRAM (e.g., RTX 3060 or higher)
- CPU: Intel i7 or AMD Ryzen 7 (or equivalent)
- RAM: 16GB or more
- Storage: At least 10GB of free disk space
Software Requirements
- Operating System: Linux or Windows
- Python: 3.8 or higher
- CUDA: Compatible version for GPU acceleration
- Dependencies: Listed in the
requirements.txtfile, including libraries like PyTorch, NumPy, and OpenCV.
🔮 Future Prospects of OmniSync
The advancements introduced by OmniSync pave the way for further innovations in lip synchronization and audio-visual synthesis. Future developments may include:
- Real-Time Lip Synchronization: Enhancing the framework to support real-time lip synchronization for live applications.
- Cross-Lingual Synchronization: Adapting OmniSync to handle lip synchronization across different languages and dialects.
- Integration with Virtual Reality (VR): Implementing OmniSync in VR environments to create immersive experiences with synchronized avatars.
These advancements could expand the applicability of OmniSync in various fields, including entertainment, education, and virtual communication.
✅ Conclusion
OmniSync represents a significant leap forward in the field of lip synchronization, offering a robust, mask-free solution that handles diverse visual scenarios and maintains high-quality synchronization. Its innovative use of Diffusion Transformers, combined with adaptive audio conditioning and progressive noise initialization, sets it apart from existing methods. As the framework continues to evolve, it holds the potential to revolutionize applications in video production, virtual communication, and beyond.
🔮 Future Scope of OmniSync
The advancements introduced by OmniSync pave the way for several exciting developments in the field of lip synchronization and audio-visual synthesis:
1. Real-Time Lip Synchronization
Enhancing OmniSync to support real-time lip synchronization could revolutionize applications in live video conferencing, virtual reality (VR), and augmented reality (AR), enabling seamless and natural interactions in real-time environments.
2. Cross-Lingual Lip Synchronization
Adapting OmniSync to handle lip synchronization across multiple languages and dialects would broaden its applicability in global communication platforms, enabling more inclusive and accessible content creation.
3. Integration with Virtual Avatars
Integrating OmniSync with virtual avatars in gaming and entertainment could lead to more immersive experiences, where avatars’ lip movements are perfectly synchronized with the audio, enhancing realism and user engagement.
4. Enhanced Audio-Visual Representation
Incorporating advanced audio-visual representations, such as facial landmarks and 3D Morphable Models (3DMM), could further improve the accuracy and quality of lip synchronization, especially in complex visual scenarios.
5. Personalized Lip Synchronization
Developing personalized lip synchronization models that adapt to individual speech patterns and facial characteristics could lead to more authentic and individualized content creation.
These future directions highlight the potential of OmniSync to transform various industries, including entertainment, education, and communication, by providing high-quality and adaptable lip synchronization solutions.
📚 References
- Ziqiao Peng, Jiwen Liu, Haoxian Zhang, Xiaoqiang Liu, Songlin Tang, Pengfei Wan, Di Zhang, Hongyan Liu, Jun He. “OmniSync: Towards Universal Lip Synchronization via Diffusion Transformers.” arXiv preprint arXiv:2505.21448, 2025.
- Soumik Mukhopadhyay, Saksham Suri, Ravi Teja Gadde, Abhinav Shrivastava. “Diff2Lip: Audio Conditioned Diffusion Models for Lip-Synchronization.” arXiv preprint arXiv:2308.09716, 2023.
- Xulin Fan, Heting Gao, Ziyi Chen, Peng Chang, Mei Han, Mark Hasegawa-Johnson. “SyncDiff: Diffusion-based Talking Head Synthesis with Bottlenecked Temporal Visual Prior for Improved Synchronization.” arXiv preprint arXiv:2503.13371, 2025.
- Chunyu Li, Chao Zhang, Weikai Xu, Jinghui Xie, Weiguo Feng, Bingyue Peng, Weiwei Xing. “LatentSync: Audio Conditioned Latent Diffusion Models for Lip Sync.” arXiv preprint arXiv:2412.09262, 2024.
- Ziqiao Peng. “OmniSync: Towards Universal Lip Synchronization via Diffusion Transformers.” OmniSync Project Page, 2025.

