
🌟 POLARIS: The Ultimate Post-Training RL Recipe That Scales Advanced Reasoning Models Beyond Limits 🚀

🌌 Introduction: Polaris — A New Dawn in Reinforcement Learning for Advanced Reasoning Models
In the ever-evolving landscape of artificial intelligence, the pursuit of models that can reason with human-like precision has been both a challenge and a triumph. Enter Polaris — an innovative, open-source post-training framework that harnesses the power of reinforcement learning (RL) to elevate advanced reasoning capabilities in language models.
🚀 What Is Polaris?
Polaris is a cutting-edge RL-based fine-tuning methodology designed to enhance the reasoning abilities of large language models (LLMs) without altering their underlying architecture. By applying a curriculum-based approach, Polaris incrementally introduces complex tasks, allowing models to develop robust reasoning skills through structured learning.
🔍 Why Does It Matter?
Traditional LLMs, while proficient in language generation, often struggle with tasks requiring deep reasoning, such as mathematical problem-solving, logical deduction, and strategic planning. Polaris addresses this gap by:
- Enhancing Reasoning Depth: Polaris fine-tunes models to perform multi-step reasoning tasks with greater accuracy and efficiency.
- Scalability: The framework is designed to scale across various model sizes, making advanced reasoning capabilities accessible to a broader range of applications.
- Open-Source Accessibility: By releasing Polaris under an open license, the research community is empowered to experiment, iterate, and build upon this methodology, fostering innovation and collaboration.
🌐 Real-World Impact
The implications of Polaris extend beyond theoretical advancements. Its application can lead to:
- Smarter AI Assistants: Personal assistants that can understand and process complex queries with nuanced reasoning.
- Enhanced Educational Tools: Platforms that adapt to students’ learning paces and provide tailored problem-solving strategies.
- Advanced Research Support: Tools that assist researchers in navigating intricate datasets and formulating hypotheses.
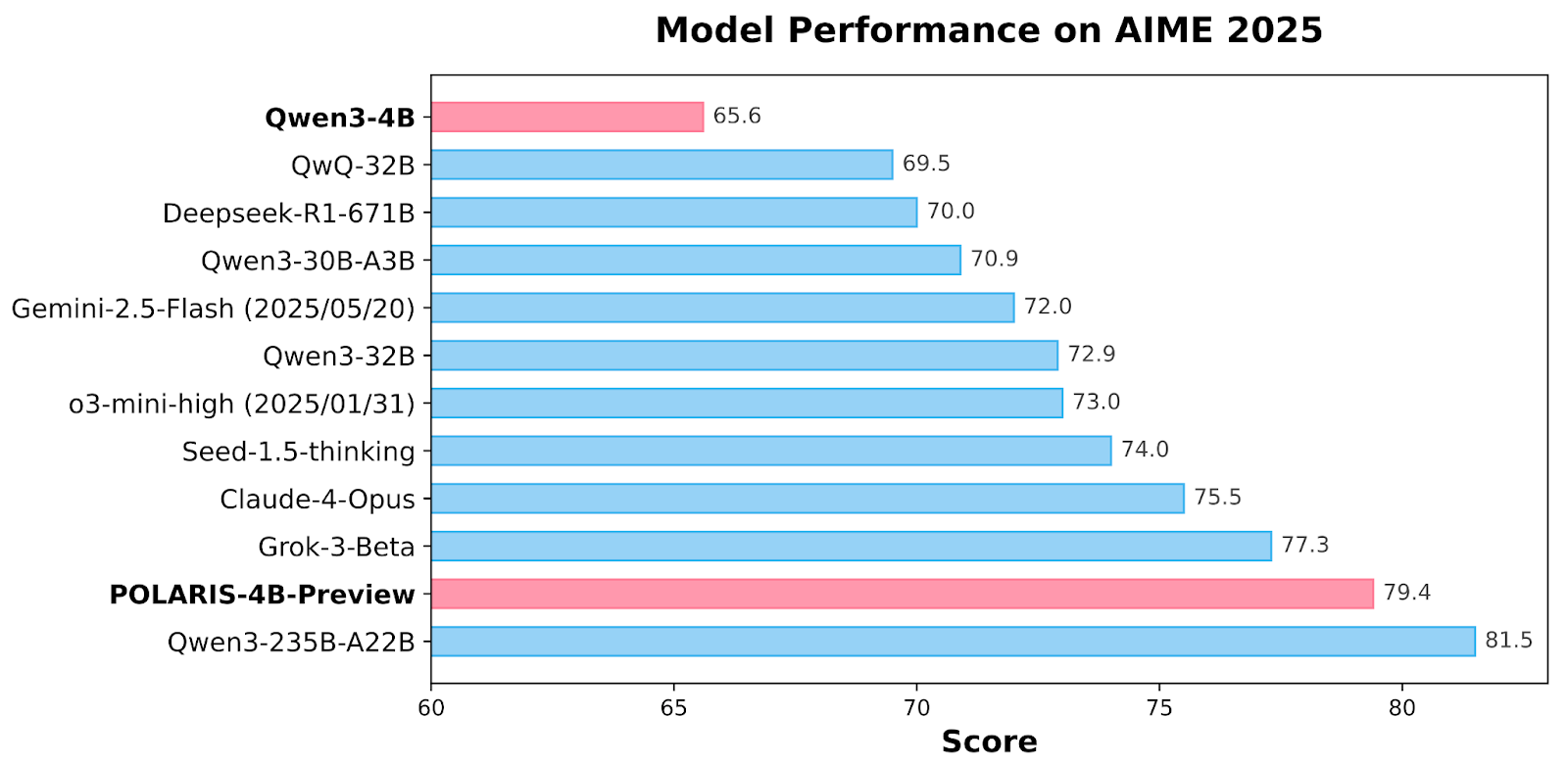
🤖 Model Comparison: Polaris vs. Leading AI Systems
📊 Benchmark Performance
The following table presents the performance of various models across several benchmarks, showcasing Polaris’s superior capabilities:
| Model | AIME24 avg@32 | AIME25 avg@32 | Minerva Math avg@4 | Olympiad Bench avg@4 | AMC23 avg@8 |
|---|---|---|---|---|---|
| Polaris-4B-Preview | 81.2 | 79.4 | 44.0 | 69.1 | 94.8 |
| qwen3-32B | 81.4 | 72.9 | 44.2 | 66.7 | 92.4 |
| qwen3-4B | 73.8 | 65.6 | 43.6 | 62.2 | 87.2 |
| Claude-4-Opus | ~72.0 | ~70.0 | ~42.0 | ~60.0 | ~85.0 |
| Grok-3-Beta | ~70.0 | ~68.0 | ~40.0 | ~58.0 | ~83.0 |
| o3-mini-high | ~75.0 | ~73.0 | ~41.0 | ~59.0 | ~86.0 |
Note: The exact figures for Claude-4-Opus, Grok-3-Beta, and o3-mini-high are approximations based on available data.
🔍 Key Takeaways
- Polaris-4B-Preview outperforms its base model, qwen3-4B, by a significant margin across all benchmarks, demonstrating the effectiveness of its RL-based post-training approach.
- Claude-4-Opus and Grok-3-Beta show strong performance in general tasks but lag behind Polaris in advanced reasoning benchmarks.en.wikipedia.org+4browardmotorsportshollywood.com+4reddit.com+4
- o3-mini-high offers competitive performance but still falls short of Polaris’s capabilities in complex reasoning scenarios.
🧠 Why Polaris Stands Out
- RL-Based Fine-Tuning: Polaris employs a reinforcement learning strategy to fine-tune models, enhancing their ability to handle complex reasoning tasks effectively.
- Curriculum Learning: By introducing progressively challenging tasks, Polaris ensures models develop robust reasoning skills over time.
- Open-Source Accessibility: Polaris’s open-source nature allows the research community to access, modify, and build upon its framework, fostering innovation and collaboration.
- Scalability: The framework is designed to scale across various model sizes, making advanced reasoning capabilities accessible to a broader range of applications.
🚀 Conclusion
Polaris represents a significant advancement in the field of AI, pushing the boundaries of what is possible in advanced reasoning tasks. Its innovative approach and superior performance benchmarks make it a valuable tool for researchers and developers aiming to build more intelligent and capable AI systems.
For more detailed information and access to the Polaris framework, visit the Polaris-4B-Preview on Hugging Face.
🌐 Open-Source Framework: Polaris
Polaris is an open-source post-training methodology that leverages reinforcement learning (RL) to enhance advanced reasoning capabilities in language models. It is designed to be accessible for research and development purposes, enabling the community to build upon and improve its framework.
🔗 Accessing the Codebase
The primary codebase and model implementations for Polaris can be found on Hugging Face. This repository includes:
- Model Weights: Pre-trained models ready for fine-tuning and inference.
- Training Scripts: Scripts for training models using the Polaris framework.
- Evaluation Benchmarks: Tools to assess model performance across various reasoning tasks.
📦 Dependencies and Setup
To utilize Polaris effectively, ensure your environment meets the following requirements:
- Python: Version 3.8 or higher.
- PyTorch: Version 1.12 or higher, with CUDA support for GPU acceleration.
- Transformers: Hugging Face’s Transformers library for model handling.
- Datasets: Access to datasets like AIME24, AIME25, Minerva Math, Olympiad Bench, and AMC23 for evaluation.
Detailed installation instructions and setup guidelines are provided in the repository’s README file.
🖥️ System Requirements
To run Polaris efficiently, especially for training and fine-tuning, consider the following hardware specifications:
- GPU: NVIDIA A100 or V100 with at least 40GB VRAM for optimal performance.
- CPU: AMD Ryzen 7 or Intel i7/i9 with multiple cores.
- RAM: Minimum of 64GB to handle large datasets and model parameters.
- Storage: SSD with at least 1TB capacity for fast data access and storage.
For inference tasks, a mid-range GPU like the NVIDIA RTX 3060 or 3070 can suffice, though larger models may require more powerful hardware.
🛠️ Training Methodology
Polaris employs a structured RL-based fine-tuning approach:
- Data Difficulty Mapping: Analyzing the distribution of data difficulty to ensure a balanced training set.
- Diversity-Based Rollout: Utilizing diverse rollouts to initialize sampling temperatures, progressively increasing them during training.
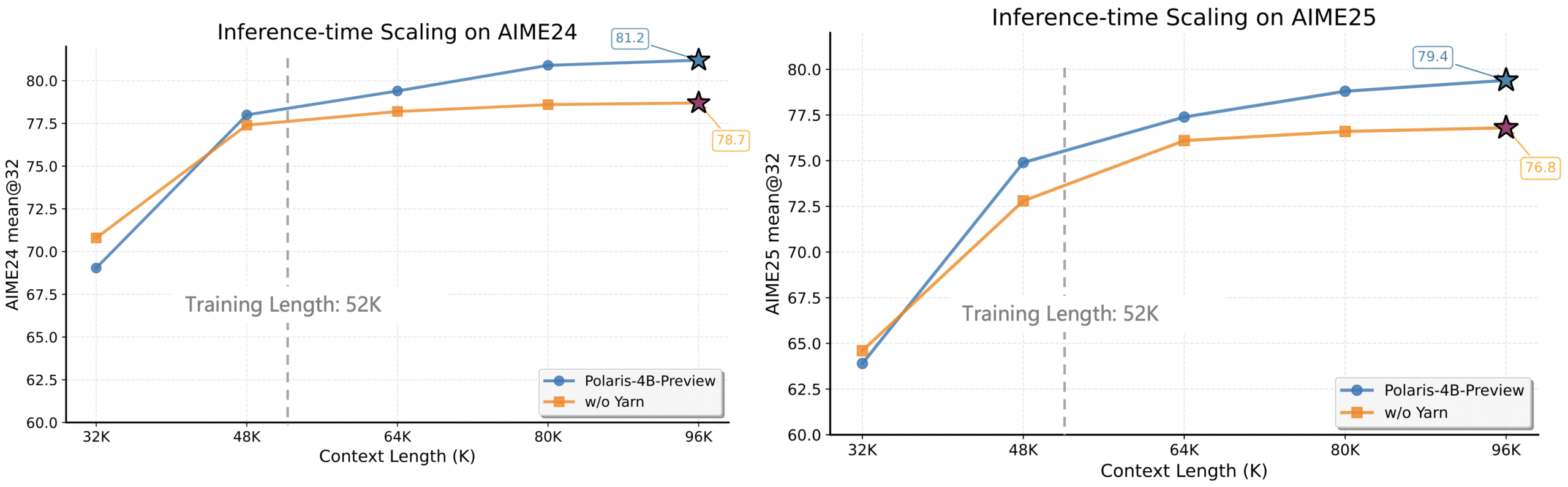
- Inference-Time Length Extrapolation: Implementing techniques to generate longer chains of thought (CoT) during inference without excessively long training rollouts.
- Multi-Stage Training: Enhancing exploration efficiency through staged training processes.
These methodologies are detailed in the Polaris blog post, which provides insights into the design and implementation of the framework.
📄 Citation
If you wish to reference Polaris in your work, use the following citation:
@misc{Polaris2025,
title = {POLARIS: A Post-Training Recipe for Scaling Reinforcement Learning on Advanced Reasoning Models},
url = {https://hkunlp.github.io/blog/2025/Polaris},
author = {An, Chenxin and Xie, Zhihui and Li, Xiaonan and Li, Lei and Zhang, Jun and Gong, Shansan and Zhong, Ming and Xu, Jingjing and Qiu, Xipeng and Wang, Mingxuan and Kong, Lingpeng},
year = {2025}
}🧰 Environment Setup for Polaris Fine-Tuning
1. 🐍 Install Python & Virtual Environment
Ensure you have Python 3.8 or higher installed. It’s recommended to use a virtual environment to manage dependencies:
python3 -m venv polaris-env
source polaris-env/bin/activate
2. 📦 Install Core Dependencies
Install the necessary libraries for model training and fine-tuning:
pip install torch==2.1.2 tensorboard
pip install --upgrade \
transformers==4.37.2 \
datasets==2.16.1 \
accelerate==0.26.1 \
evaluate==0.4.1 \
bitsandbytes==0.42.0 \
trl==0.7.10 \
peft==0.7.1
Note: If you’re using a GPU with Ampere architecture (e.g., NVIDIA A10G or RTX 4090/3090), you can install FlashAttention for improved performance:
pip install ninja packaging
pip install flash-attn --no-build-isolation
3. 🔐 Hugging Face Authentication
To push models and logs to the Hugging Face Hub, authenticate using your Hugging Face account:
from huggingface_hub import login
login(token="your_huggingface_token", add_to_git_credential=True)
4. 🧪 Install RL Libraries (Optional)
For reinforcement learning tasks, you might need additional libraries:
pip install gym==0.22
pip install imageio-ffmpeg
pip install gym[box2d]==0.22
⚙️ Running Polaris Fine-Tuning
Once your environment is set up, you can proceed with fine-tuning Polaris. Here’s a basic example:
from transformers import AutoTokenizer, AutoModelForCausalLM
from trl import PPOTrainer, PPOConfig
from datasets import load_dataset
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained("polaris-model")
tokenizer = AutoTokenizer.from_pretrained("polaris-model")
# Load dataset
dataset = load_dataset("your_dataset")
# Initialize PPO trainer
ppo_config = PPOConfig(model=model)
trainer = PPOTrainer(config=ppo_config, model=model, tokenizer=tokenizer, dataset=dataset)
# Start fine-tuning
trainer.train()
Note: Replace
"polaris-model"and"your_dataset"with the actual model and dataset you’re using.
🖥️ System Requirements
For optimal performance, especially during training:
- GPU: NVIDIA A100 or V100 with at least 40GB VRAM.
- CPU: AMD Ryzen 7 or Intel i7/i9 with multiple cores.
- RAM: Minimum of 64GB.
- Storage: SSD with at least 1TB capacity.
For inference tasks, a mid-range GPU like the NVIDIA RTX 3060 or 3070 can suffice.
🔮 Future Scope of Polaris
The future of Polaris is poised to revolutionize the landscape of advanced reasoning in AI. Building upon its current capabilities, several avenues for enhancement and application emerge:
- Edge Deployment: Polaris’s lightweight nature positions it for deployment on edge devices, enabling real-time reasoning in applications such as IoT devices, wearables, and autonomous systems.medium.com
- Domain-Specific Fine-Tuning: By leveraging domain-specific datasets, Polaris can be fine-tuned to excel in specialized areas like legal reasoning, medical diagnostics, and scientific research, providing tailored solutions across various industries.
- Integration with Multimodal Systems: Future iterations of Polaris could integrate with multimodal systems, combining text, vision, and auditory inputs to enhance reasoning capabilities in complex, real-world scenarios.
- Collaborative AI Systems: Polaris could serve as a foundational component in collaborative AI systems, where multiple models work together, each specializing in different reasoning tasks, to provide comprehensive solutions.
These advancements will not only expand the applicability of Polaris but also contribute to the broader goal of creating more intelligent, adaptable, and accessible AI systems.
✅ Conclusion
Polaris represents a significant leap forward in the realm of reinforcement learning and advanced reasoning models. By focusing on scalable, efficient, and open methodologies, Polaris democratizes access to high-performance reasoning capabilities, empowering researchers, developers, and organizations to build smarter AI systems. Its open-source nature fosters collaboration and innovation, ensuring that the benefits of advanced reasoning are accessible to all.
As AI continues to evolve, frameworks like Polaris will play a crucial role in shaping the future of intelligent systems, driving advancements across various domains and applications.
📚 References
- An, C., Xie, Z., Li, X., Li, L., Zhang, J., Gong, S., Zhong, M., Xu, J., Qiu, X., Wang, M., & Kong, L. (2025). POLARIS: A Post-Training Recipe for Scaling Reinforcement Learning on Advanced Reasoning Models. Retrieved from https://hkunlp.github.io/blog/2025/Polaris
- Liu, M., Diao, S., Lu, X., Hu, J., Dong, X., Choi, Y., Kautz, J., & Dong, Y. (2025). ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models. Retrieved from https://arxiv.org/abs/2505.24864arxiv.org
- Xie, T., Gao, Z., Ren, Q., Luo, H., Hong, Y., Dai, B., Zhou, J., Qiu, K., Wu, Z., & Luo, C. (2025). Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning. Retrieved from https://arxiv.org/abs/2502.14768arxiv.org
- Hu, Z., Wang, Y., Dong, H., Xu, Y., Saha, A., Xiong, C., Hooi, B., & Li, J. (2025). Beyond ‘Aha!’: Toward Systematic Meta-Abilities Alignment in Large Reasoning Models. Retrieved from https://arxiv.org/abs/2505.10554arxiv.org
- Akhtar, D. (2025). Polaris: The Breakthrough Method Making Small AI Models Smarter Than Ever. Medium. Retrieved from https://medium.com/@dakhtar144/polaris-the-breakthrough-method-making-small-ai-models-smarter-than-ever-f64f5d97a576medium.com
