✨ AnimaX: Bringing 3D Models to Life with Video-Based Pose Animation
🧠 Introduction
Animating 3D models—especially those with complex skeletal structures—has traditionally been a laborious process, requiring either rigid rigs or expensive optimizations in deformation spaces. AnimaX revolutionizes this by leveraging the rich motion knowledge embedded in video diffusion models and translating it into controllable 3D animations.
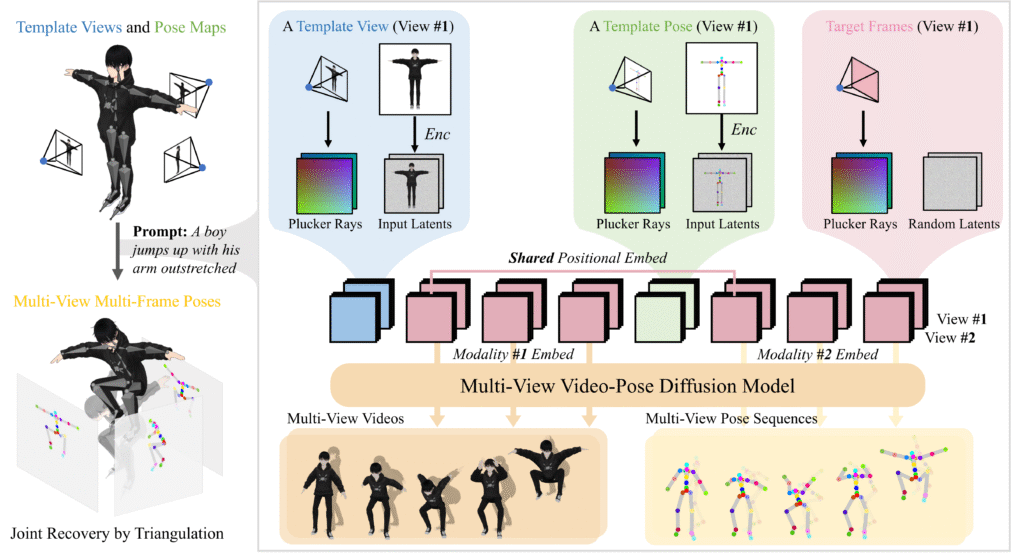
At its core, AnimaX interprets motion as a sequence of 2D pose maps captured from multiple camera views alongside RGB frames. These are then processed through a joint video‑pose diffusion model, which is conditioned on template renders of a 3D mesh and a textual motion prompt. The model’s clever fusion of modalities is achieved through:
- A 3D Variational Autoencoder (VAE) paired with a Diffusion Transformer (DiT) to encode both video frames and pose inputs into a shared latent space.
- Shared positional encodings and modality-aware embeddings that tightly align RGB and pose data across space and time.
- Camera-aware attention mechanisms, incorporating representations like Plücker ray maps, ensuring cross-view consistency during generation.
Post-generation, the model reconstructs 3D motion by triangulating multi-view 2D keypoints and fitting them to the mesh using inverse kinematics, transforming abstract pose sequences into smooth skeletal animation.
Trained on a vast dataset of ~160,000 rigged mesh animations, AnimaX achieves state-of-the-art results on benchmarks like VBench, demonstrating superior generalization, motion fidelity, and efficiency—with animation generation taking around six minutes.
Why it matters:
AnimaX offers a feed-forward, highly generalizable animation pipeline that applies to a wide range of articulated 3D models—from humans to animals—without needing predefined topologies. By exploiting video-based motion priors in a pose-centric framework, it marks a significant leap toward democratizing realistic 3D animation.
📝 Description & Creators
AnimaX is a cutting-edge framework that breathes life into static 3D meshes using motion patterns learned from real videos. Instead of relying on hand-crafted rigs or fine-tuning for each model, it leverages powerful video diffusion priors and translates them into controllable skeletal animations.
👤 Creators
The AnimaX team, based on an ArXiv publication dated June 24, 2025, comprises:
- Zehuan Huang
- Haoran Feng
- Yangtian Sun
- Yuanchen Guo
- Yanpei Cao
- Lu Sheng
These researchers present a novel method to animate a wide variety of 3D characters—whether humans, animals, or fictional creatures—without needing custom rigs or extensive deformation logic.
🧩 Core Methodology
- Pose + Video Diffusion Backbone
- Multi-view 2D pose maps and RGB video frames are coupled using a joint video–pose diffusion model.
- A 3D VAE encodes template views, then a Diffusion Transformer (DiT) generates multi-view, multi-frame pose and RGB outputs.
- Shared Positional Encoding
- RGB and pose modalities use the same positional codes across space and time, ensuring precise alignment.
- Camera-Aware Multi-View Attention
- Plücker ray maps encode camera views across multiple perspectives, enabling consistent and cohesive motion generation.
- Pose Extraction & 3D Reconstruction
- 2D poses are extracted from the diffusion outputs and triangulated to reconstruct 3D joint positions.
- Perform inverse kinematics to animate the mesh according to the predicted skeletal motion.
- Large-Scale Training
- Trained on ~160,000 rigged motion sequences from datasets like Objaverse and Mixamo.
- Demonstrates strong generalization across new categories and skeletons.
⚡ Highlights
- Category-Agnostic: Works seamlessly with any articulated mesh—human, animal, or fantasy.
- Feed-Forward & Efficient: Produces animations in ~6 minutes per sequence—no iterative fitting needed .
- Spatial-Temporal Alignment: Fuses RGB appearance and pose modalities with shared encodings for high-fidelity motion.
- State-of-the-Art: Achieves top scores on VBench benchmarks for motion quality, realism, and generalizability.
⚔️ Comparison with Other 3D Animation Models
| Feature | AnimaX | Animate3D / MotionDreamer |
|---|---|---|
| Generalization | Works on arbitrary articulated meshes (humans, animals, creatures) | Often limited to specific skeleton types or deformable models |
| Training Data | ~160,000 rigged sequences (Objaverse, Mixamo, VRoid) | Smaller/no shared dataset, specialized per task |
| Diffusion Approach | Joint video–pose diffusion conditioned on template views and text | Video diffusion alone; lacks pose conditioning |
| Spatial-Temporal Alignment | Shared positional encoding across RGB + poses ensures high coherence | No explicit alignment; relies on video context only |
| View Consistency | Multi-view attention with camera pose integration | Single-view or limited context, no multi-camera coherence |
| 3D Reconstruction | 2D pose extraction, triangulation, inverse kinematics to animate mesh | Limited/no post-generation IK pipeline |
| Runtime Efficiency | Feed-forward inference (~6 min per animation) | Typically slower, optimization-based generation |
| Benchmarking | State-of-the-art on VBench for motion fidelity and generalization | Lower performance, often outperformed by AnimaX |
Summary:
AnimaX stands out by combining video diffusion priors with explicit skeletal conditioning and multi-view awareness. This gives it superior generalization, motion coherence, and efficiency compared to Animate3D and MotionDreamer.
🏗️ Architecture Details (check Project Page )
AnimaX is a feed-forward 3D animation framework that combines video diffusion priors and skeletal control, enabling animation of diverse articulated meshes without requiring rigid rigs or object-specific optimizations.
1. Multi-View Video-Pose Diffusion Model
- Represents motion as multi-view, multi-frame 2D pose maps plus RGB frames.
- Conditioned on template views (kind of static renders of the mesh) and a textual prompt.
- Built on a 3D VAE to encode both input and target into latent space, followed by a Diffusion Transformer (DiT) to denoise joint video–pose noised latents.
2. Shared Positional & Modality-Aware Embeddings
- Enforces spatial-temporal alignment by using shared positional encodings (via RoPE) across RGB and pose tokens.
- Distinguishes RGB vs pose inputs using modality embeddings, ensuring cross-modal consistency.
3. Camera-Aware Multi-View Attention
- Integrates camera pose information (e.g., Plücker ray maps) into attention layers to ensure alignment across multiple views.
4. 3D Reconstruction via Pose Triangulation
- After generating multi-view 2D poses, the system triangulates joint positions across views, then applies inverse kinematics to fit a skeleton to the mesh and animate it.
5. Two-Stage Training
- Single-View Fine-Tuning – LoRA-based adaptation of the video backbone using paired RGB+pose data.
- Multi-View Attention Tuning – Trains camera-aware attention layers while keeping the backbone fixed .
💻 System Requirements
🖥️ Hardware
| Task | GPU | CPU / RAM | Storage |
|---|---|---|---|
| Training | Multi‑GPU setup (NVIDIA A100/H100) | 16+ CPU cores, 128 GB RAM | NVMe SSD (~2 TB) |
| Inference | 1–2 GPUs (e.g., RTX 3090, 24 GB VRAM) | 8+ cores, 32 GB RAM | SSD (~500 GB) |
🧰 Software
- OS: Ubuntu 20.04+ (Linux recommended)
- Python: Version 3.8+
- CUDA: Toolkit v11 or higher
- Libraries:
torch(for VAE & transformer training)diffusers/transformersOpenCV,numpy- 3D tools: for triangulation and inverse kinematics (e.g.,
pybullet,trimesh,ibex)
- Optional:
- Rendering pipelines (e.g.,
Blender Python,PyTorch3D) - LoRA / adapter frameworks (for training efficiency)
- Rendering pipelines (e.g.,
⚙️ Tips & Caveats
- Data Preparation: Requires multi-view template renders and corresponding pose maps (e.g., from OpenPose).
- VRAM Usage: Shared positional encodings and multi-view processing are memory intensive—adjust batch size or view count as needed.
- Inference Time: Animation of one mesh typically completed in ~6 minutes using capable hardware
🛠️ Installation Guide
Eager to try out AnimaX? Here’s how to get it up and running.
🔧 Step 1: Clone the Repository
git clone https://github.com/anima-x/animax.git
cd animax
📦 Step 2: Environment Setup
python3 -m venv animax-env
source animax-env/bin/activate
pip install -r requirements.txt
Dependencies include:
torch,diffusers,transformersopencv-python,numpy- 3D libraries:
trimesh,pybullet,pyrender
📝 Step 3: Download Pre-trained Models
From the project’s Hugging Face repository or AWS bucket:
scripts/download_pretrained.sh
This fetches:
- Video–pose diffusion model weights
- Camera-aware attention modules
🎥 Step 4: Prepare Template Data
Render N static template views (RGB + pose images) of your 3D mesh. Ensure pose maps come in the same format as training (e.g., OpenPose heatmaps).
🚀 Step 5: Generate Animation
python scripts/infer.py \
--template_dir path/to/template_views \
--prompt "a dog wagging its tail" \
--output_dir outputs/
The script produces multi-view pose and RGB sequences, triangulates joints, and applies inverse kinematics to animate your mesh.
💡 Tips for Effective Usage
- Template Quality: Use clear, evenly spaced template views to improve triangulation accuracy.
- GPU VRAM: Use at least 24 GB VRAM (e.g., RTX 3090). For multi-view or higher-res runs, prefer A100/H100 GPUs.
- Batching Strategy: Generate views in batches to manage GPU memory effectively.
- Adjust View Count: The default is 3–4 views. More views improve consistency but use more memory and computation.
🔮 Future Work
- Flexible Camera Paths & Viewpoints
Extend beyond fixed multi-view templates by enabling dynamic and arbitrary camera trajectories, addressing current limitations tied to static viewpoints. - Longer or Autoregressive Animations
Explore autoregressive generation or test-time training to produce extended or continuous animation sequences, mitigating limitations of short fixed-length outputs. - Broader Articulation and Control
Introduce precise control over specific joints or body parts, and support finer-grained edits, such as facial expressions or finger articulations. - Enhanced Physical Realism
Incorporate physics-based constraints—collisions, dynamics, grip—to elevate realism and applicability in simulations, games, and interactive environments. - Streaming & Edge Deployment
Develop lightweight, optimized versions of AnimaX suitable for real-time animation on edge devices or game engines—critical for interactive and VR/AR applications.
✅ Conclusion
AnimaX bridges rich motion patterns from video diffusion models with skeleton-based control to animate arbitrary 3D meshes—including humans, animals, and fictional creatures. By combining:
- Joint video–pose diffusion modeling,
- Shared positional encodings,
- Camera-aware attention,
- And a scalable 3D reconstruction pipeline,
…it delivers feed-forward, high-quality animations in minutes, achieving state-of-the-art performance on benchmarks like VBench. The framework’s efficiency, generality, and motion fidelity mark a significant advance beyond previous approaches like Animate3D and MotionDreamer.
📚 References
- Huang, Z., Feng, H., Sun, Y., Guo, Y., Cao, Y., & Sheng, L. (2025). AnimaX: Animating the Inanimate in 3D with Joint Video‑Pose Diffusion Models. arXiv:2506.19851 arxiv.org+2themoonlight.io+2themoonlight.io+2ar5iv.labs.arxiv.org+7huggingface.co+7paperledge.com+7
- Jiang, Y., Yu, C., Cao, C., Wang, F., Hu, W., & Gao, J. (2024). Animate3D: Animating Any 3D Model with Multi‑view Video Diffusion. arXiv:2407.11398 themoonlight.io+2arxiv.org+2themoonlight.io+2
- Benedí San Millán, M., Dai, A., & Nießner, M. (2025). Animating the Uncaptured: Humanoid Mesh Animation with Video Diffusion Models. arXiv:2503.15996