🗣️ Chatterbox: Resemble AI’s Open-Source TTS Model Outperforms ElevenLabs with Emotion Control
Posted in :
🧭 Introduction
In the realm of Text-to-Speech (TTS) technology, achieving natural, expressive, and customizable voice synthesis has been a significant challenge. Resemble AI’s Chatterbox emerges as a groundbreaking solution, offering an open-source TTS model that not only delivers high-quality voice synthesis but also introduces innovative features like emotion exaggeration control. Licensed under the MIT License, Chatterbox is designed to empower developers, content creators, and enterprises to integrate lifelike voice capabilities into their applications.
🔍 Key Features of Chatterbox
🎭 Emotion Exaggeration Control
One of Chatterbox’s standout features is its emotion exaggeration control, enabling users to adjust the intensity of emotions in the synthesized speech. This capability allows for more dynamic and engaging voice outputs, making it ideal for applications requiring expressive and nuanced speech synthesis.
⚡ High Performance
Chatterbox delivers ultra-low latency of sub-200ms, ensuring real-time voice generation that’s crucial for interactive applications such as AI agents, gaming, and live customer support. This performance benchmark positions Chatterbox as a competitive alternative to leading closed-source TTS systems.
🧪 Open Source and Customizable
Licensed under the MIT License, Chatterbox is fully open-source, allowing developers to inspect, modify, and integrate the model into their applications. Its flexibility makes it suitable for a wide range of use cases, from content creation to enterprise solutions.
📊 Benchmarking Against ElevenLabs
In a recent evaluation, Chatterbox was benchmarked against ElevenLabs, a leading closed-source TTS system. The results indicated that Chatterbox, with its emotion exaggeration control and open-source nature, offers a compelling alternative to ElevenLabs, especially for developers seeking customizable and expressive TTS solutions.
🚀 Real-World Applications
🎮 Gaming
Chatterbox can be used to generate character voices with varying emotional tones, enhancing the gaming experience by making dialogues more immersive and relatable.
🎥 Content Creation
Content creators can leverage Chatterbox to produce voiceovers for videos, tutorials, and podcasts, with the ability to adjust emotional intensity to match the content’s mood.
🤖 AI Agents
Integrating Chatterbox into AI agents allows for more natural and engaging interactions, as the model can convey emotions that align with the agent’s responses.
🌐 Try Chatterbox Today
Experience Chatterbox firsthand by visiting our Hugging Face Gradio app. Whether you’re a developer, content creator, or enthusiast, Chatterbox offers a powerful and expressive TTS solution to bring your projects to life.
🛠️ Installation Guide for Chatterbox
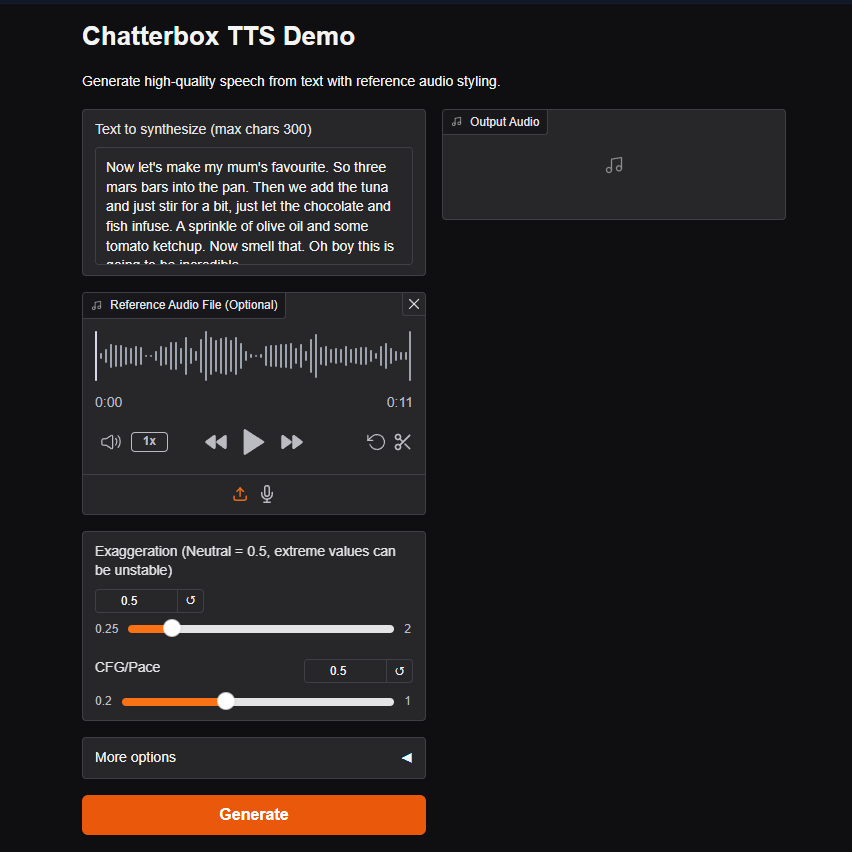
- General Use (TTS and Voice Agents):
- The default settings (
exaggeration=0.5,cfg_weight=0.5) work well for most prompts. - If the reference speaker has a fast speaking style, lowering
cfg_weightto around0.3can improve pacing.
- The default settings (
- Expressive or Dramatic Speech:
- Try lower
cfg_weightvalues (e.g.~0.3) and increaseexaggerationto around0.7or higher. - Higher
exaggerationtends to speed up speech; reducingcfg_weighthelps compensate with slower, more deliberate pacing.
- Try lower
1. Clone the Repository
Begin by cloning the official Chatterbox repository from GitHub:
git clone https://github.com/resemble-ai/chatterbox.git
cd chatterbox
2. Set Up a Virtual Environment
It’s recommended to use a virtual environment to manage dependencies:
bashCopyEditpython3 -m venv venv
source venv/bin/activate # On Windows, use `venv\Scripts\activate`
3. Install Dependencies
Install the required Python packages:
pip install -r requirements.txt
4. Download Pre-trained Models
Chatterbox requires pre-trained models for TTS. Download them from the official source or follow the instructions provided in the repository’s README.
5. Run the Application
Start the application:
python app.py
This will launch a local server, typically accessible at http://127.0.0.1:5000.
Usage
import torchaudio as ta
from chatterbox.tts import ChatterboxTTS
model = ChatterboxTTS.from_pretrained(device="cuda")
text = "Ezreal and Jinx teamed up with Ahri, Yasuo, and Teemo to take down the enemy's Nexus in an epic late-game pentakill."
wav = model.generate(text)
ta.save("test-1.wav", wav, model.sr)
# If you want to synthesize with a different voice, specify the audio prompt
AUDIO_PROMPT_PATH="YOUR_FILE.wav"
wav = model.generate(text, audio_prompt_path=AUDIO_PROMPT_PATH)
ta.save("test-2.wav", wav, model.sr)
🎛️ Tips for Optimal Performance
- Hardware Requirements: For real-time TTS, a machine with a dedicated GPU is recommended. However, Chatterbox can run on CPU, though with reduced performance.
- Latency Considerations: If you’re experiencing high latency, consider optimizing the model or using a more powerful machine.
- Voice Customization: Chatterbox supports emotion exaggeration control. Adjust the emotional intensity parameters to achieve the desired tone in the synthesized speech.
🔄 Exploring Alternative Platforms
If you prefer not to set up Chatterbox locally, consider using cloud platforms that offer TTS services:
- Modal: Provides a platform to deploy Chatterbox as a service. Check out their documentation for more details.
- Replicate: Offers a hosted version of Chatterbox. Visit Replicate’s Chatterbox page to explore this option.
💡 Final Thoughts
Chatterbox represents a significant advancement in open-source TTS technology, offering expressive, customizable, and high-performance voice generation. Its emotion exaggeration control sets it apart from other models, providing users with the ability to create more dynamic and engaging audio content. Whether you’re developing AI agents, creating content, or exploring new possibilities in voice synthesis, Chatterbox offers the tools to bring your ideas to life.